[논문리뷰] BrainLM: A foundation model for brain activity recordings
ICLR 2024 [Paper] [huggingface]
Josue Ortega Caro, Antonio Henrique de Oliveira Fonseca, Syed A Rizvi, Matteo Rosati, Christopher Averill, James L Cross, Prateek Mittal, Emanuele Zappala, Rahul Madhav Dhodapkar, Chadi Abdallah, David van Dijk 16 Jan 2024
1. Introduction
뇌에서 어떻게 인지와 행동이 일어나는지 이해하는 것은 neuroscience research 분야에서 근본적인 chllenghes 중 하나이다. fMRI는 이를 해결할 도구중에 하나이다. 그러나 fMRI가 측정하는 BOLD 시그널은 뇌 기능의 간접적인 신호라서 해석에 어려움이 있다. 또한 fMRI는 시간과 공간에 모두 종속되는 복잡한 slatoptemporal(시공간) 역학을 나타낸다. 기존의 접근 방식은 이 복잡한 비선형적인 상호작용을 완전히 모델링하는데 실패했다.
기존의 fMRI analysis 기술들은 일반화 성능을 저해하며, 특정 task들에만 모델링했다. 또한 label이 없는 가용하며 풍부한 fMRI 데이터를 사용하는 것에 어려움을 겪었다. 본 논문에서는 NLP에서 foundation model의 획기적인 성공에 힘입어 대규모 데이터에 대하여 다목적 모델을 훈련하여 fine-tuning을 통해 downstream 기능을 활성화한다. BrainLM은 fMRI에 대한 첫 foundation model이다. Transformer 베이스의 모델을 사용하여 큰 스케일의 뇌 활성 데이터의 고유한 시공간 역학을 캡쳐한다.
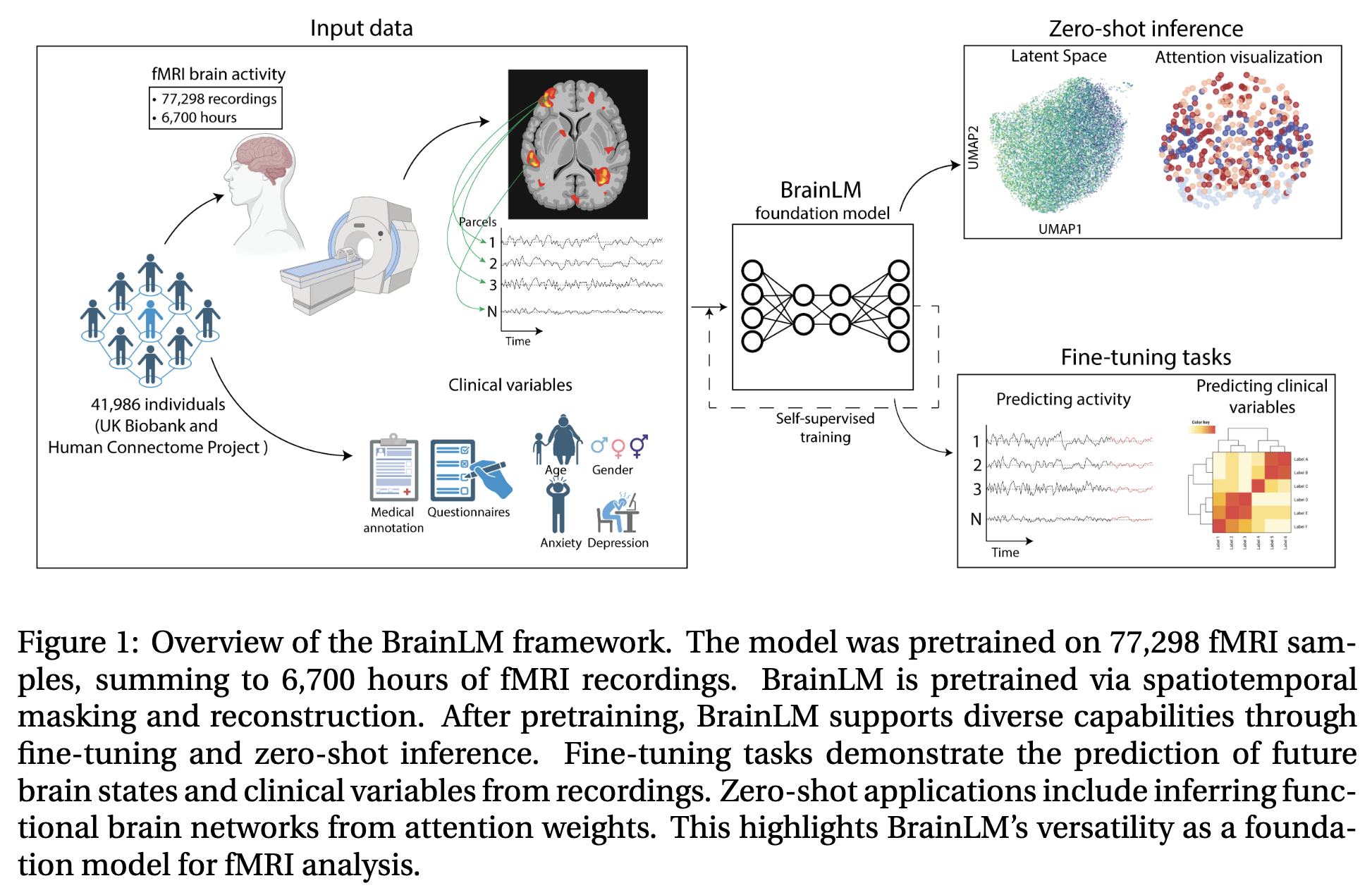
위 그림에서 볼 수 있듯이, unsupervised representation learning을 통해 다양한 downstream task에서도 일반적인 성능을 낼 수 있다. pretraining이 완료된 후에는 뛰어난 fine-tune 성능과 zero-shot 성능을 보인다.
2. Realted Work
이전 연구에서는 fMRI recording을 분석하기 위한 다양한 ML 기술을 탐구했다. SVM, NN 등을 이용하여 자극 카테고리나 관심 변수를 회귀했다. 그러나 이 모델들은 특정 task를 위해 representation을 학습했으며 따라서 일반화에 어려움을 겪었다. 최근 연구는 일반화에 힘을 많이 썼다. recordings을 recon하는 autoencoder를 학습하는 방식을 사용하곤 했는데, 이는 적은 양의 데이터셋을 사용해서 robust한 일반화 능력을 갖지는 못했다. (약 1~2배 많은 데이터로 본 논문은 MAE를 이용한다.) 또한 다른 연구들이 LLM과 brain recordings간 representational similities를 찾는데 중심을 두었는데 이 부분의 연장 선상에서 본 연구에서는 LLM과 언어 처리 영역과 같은 특정 뇌 영역 사이의 높은 상관 관계가 발견되었다. 그러나 이 논문은 뇌 역학의 foundation model을 학습하거나 downstream biological tasks를 위해 모델을 fine-tune하는 데 중점을 두지 않는다.
3. Method
3.1. Dataset ansd Preprocessing
데이터셋으로 공공 데이터 중 큰 사이즈인 Human Connectome Project (HCP)과 UK Biobank(UKB)를 사용했다. UKB는 40~69세의 robust한 76,296 task-based and resting-state functional MRI (rs-fMRI) recordings를 가지고 있으며 이는 Siemens 3T scanner로 0.735s temporal resolution로 측정한 데이터셋이다. HCP는 건강한 성인의 1,002 high-quality fMRI recordings를 0.72s resolution으로 측정한 데이터셋이다.
BrainLM은 UKB 80%로 학습하고, 나머지 20%와 HCP 데이터로 검증한다. 모든 recordings는 데이터 준비를 위해 motion correction, normalization, temporal filtering, 그리고 ICA denoising 까지 standard preprocessing을 거쳤다. parcel-wise time series를 추출하기 위해 AAL-424 atlas를 사용했다. 이는 424D의 ~1Hz로 샘플링된 시퀀스를 산출하게 된다. 각 parcel별로 환자들을 Robust scaling을 함으로 전처리를 마무리 한다. 따라서 6,700시간의 77,298 recordings을 얻었으며 이런 큰 데이터셋이 BrainLM으로 하여금 robust functional representations을 학습하도록 한다.
3.2. Model Architecture & Training Procedure
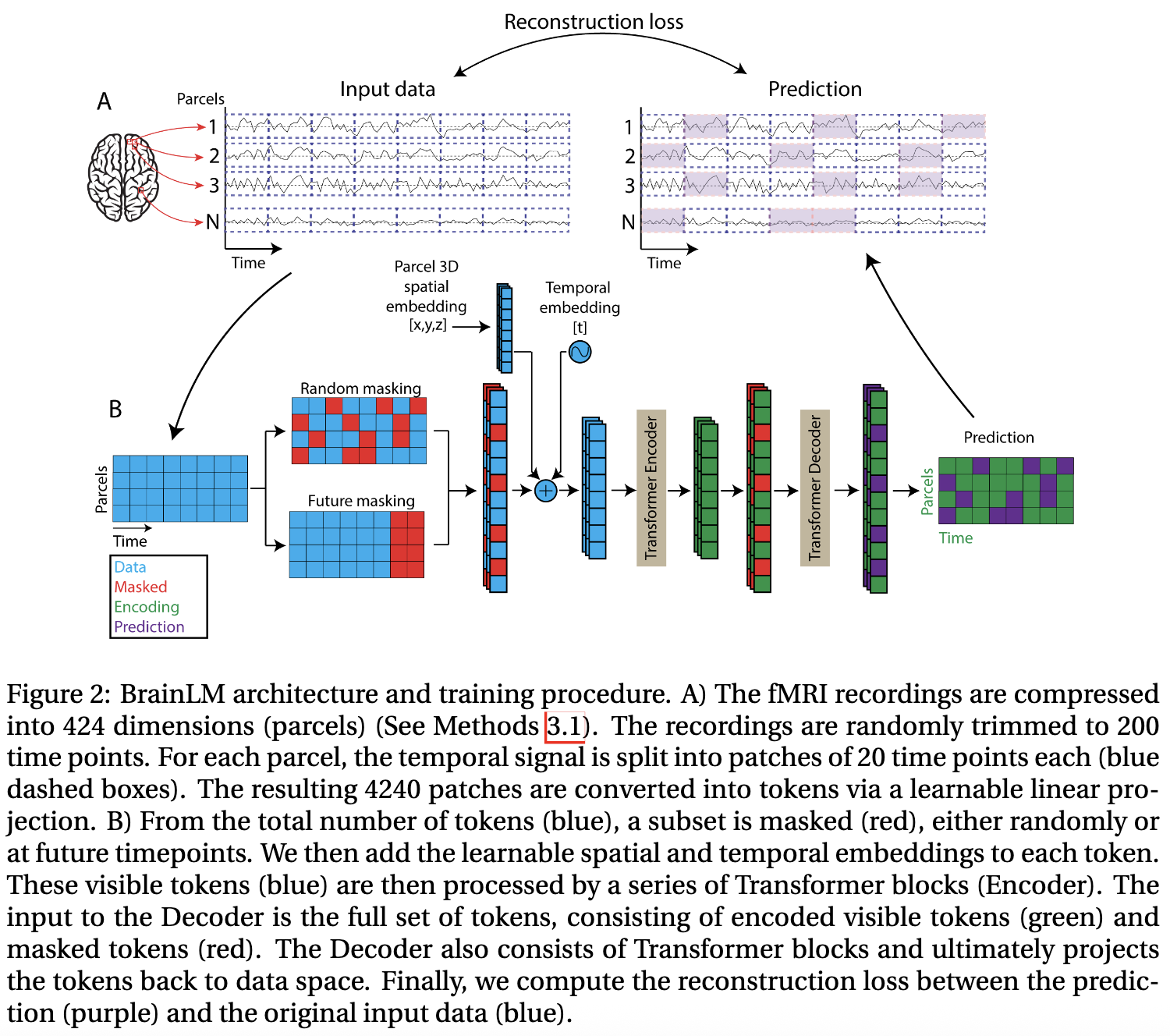
본 모델은 전적으로 MAE 기반의 Transformer를 사용한다. 이것의 핵심에는 마스킹 된 패치의 원래 신호를 예측하는 것이다. 자세한 사항은 위 그림을 참조하면 된다.
학습 시에 랜덤으로 200 timestep의 subsequence를 선택하고 20 timestep으로 쪼개의 10개의 겹치지 않는 조각으로 나누다. 이 조각은 512D의 벡터로 변형되고 20%, 75%, 90% 이율로 마스킹한다. 100M 이상의 모델에 확장하기 위해 CV 쪽에서 영감을 받아 alternative masking 전략을 채택한다. 따라서 424 parcel 별로 랜덤하게 200 timestep의 window를 2D 이미지로 처리한다.이렇게 하면 brain region의 locality를 보존하고(뇌의 해부학적 인접성을 유지) multi-parcel encoding을 허용하여 total token 양을 줄인다(연산 효율 증대). parcel은 공간과 관련이 있기 때문에 single-parcel보다 mult-parcel이 더 복원하기 어렵다(공간적으로 상관된 parcel들을 묶어서 한꺼번에 masking하면 모델이 인접 정보를 “커닝”할 수 없어서 더 robust한 representation을 학습하게 됨, 이는 MAE에서 random masking보다 block masking이 더 어렵고 효과적인 것과 같은 원리). masking 되지 않은 조각들만이 4개의 레이어와 4개의 헤드를 가진 Transformer로 인코딩되고 이는 레이어 2개로 구성된 디코더로 복원된다.
batch size는 512, Adam optimizer, 100 epoch으로 MSE를 최소화 하도록 학습한다.
3.3. Clinical Variable Prediction
다양한 태스크에 적용하기 위해 레이어 3개로 구성된 MLP head를 사용했으며, age, neuroticism, PTSD 그리고 anxiety disorder scores를 regress하도록 했다. age는 z-score로 정규화했으며 neuroticism은 min-max scaling했다. 나머지 두개는 log transformation을 사용하여 exponential distribution을 조절한 후 min-max scaling을 했다. 오버피팅을 피하기 위해 BrainLM과 MLP 모두 10%의 Dropout을 적용했다.
4. Results
4.1. Model Generalization
BrainLM이 UKB에서 $R^2$는 0.464로 같은 분포에서 unseen data에 대한 일반화 능력이 우수했으며, HCP에서는 0.278로 다른 분포에서도 잘 일반화되었다.
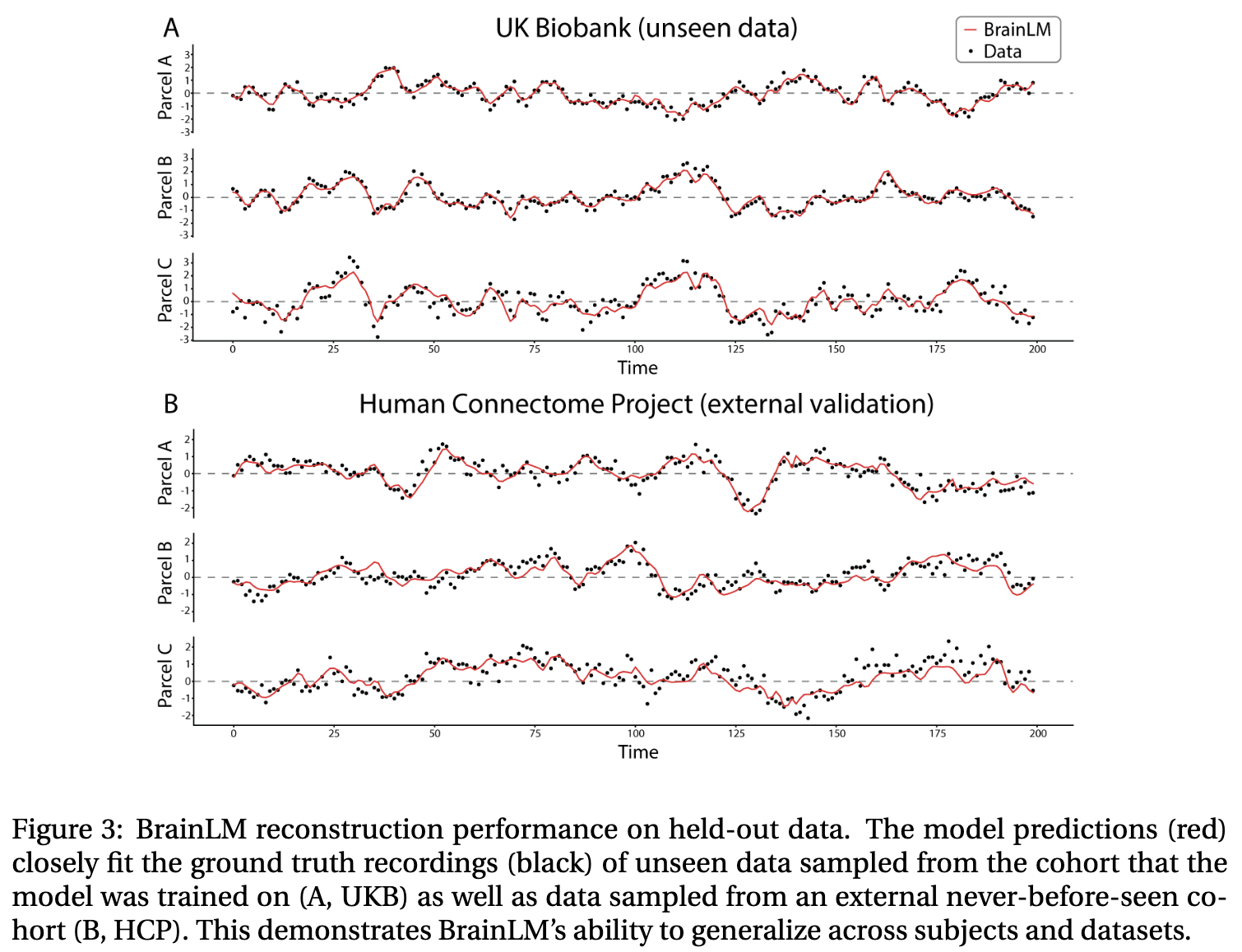
아래 그림에서 볼 수 있듯이, 모델 확장성도 강력했다.
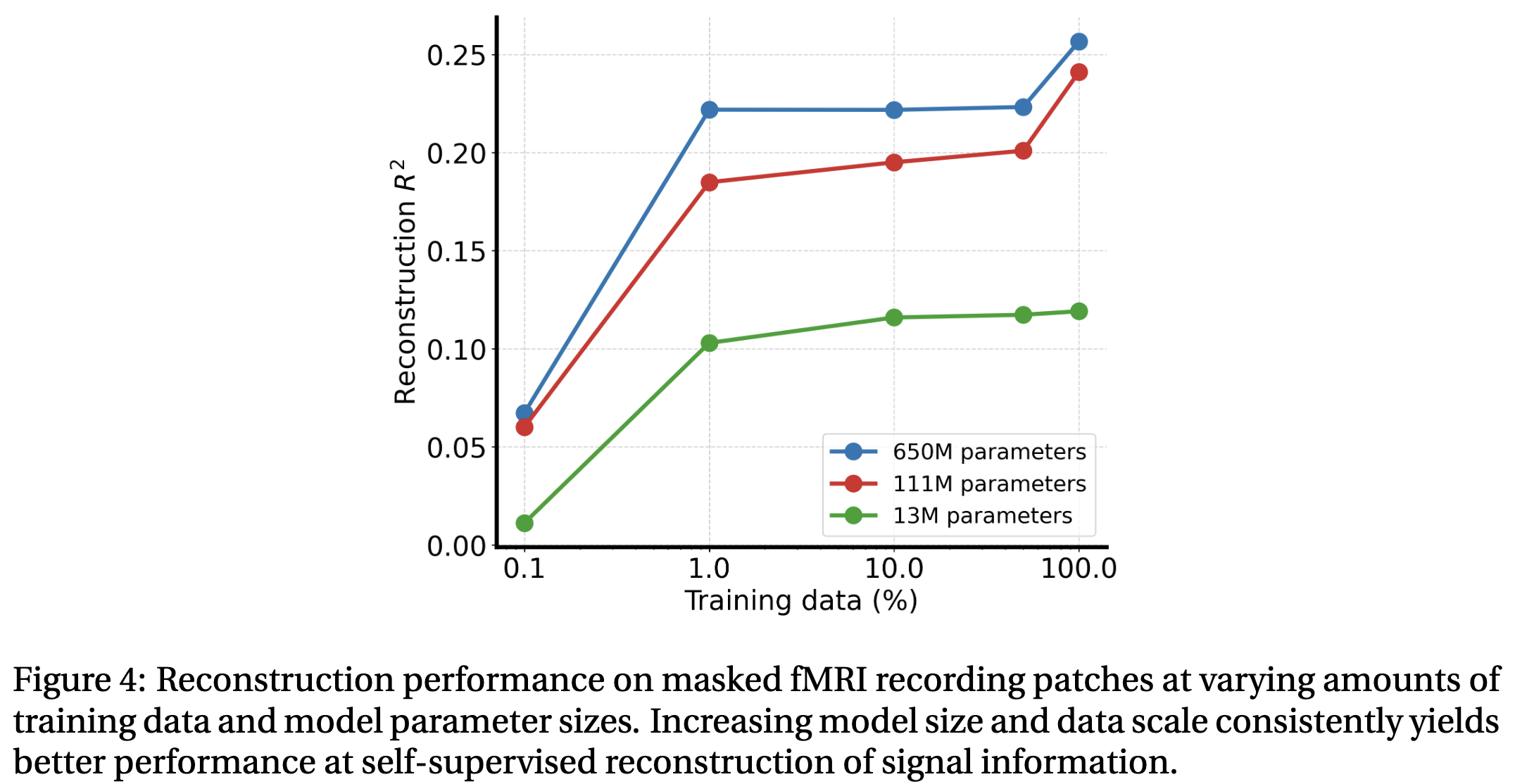
4.2. Clinical Variable Prediction
foundation mdoel의 주요한 이점 중 하나는 특정한 downstream task들에 잘 fine-tune 가능한 것이다. latent space를 조사한 결과 pretrained BrainLM은 임상에서 중요한 정보를 적절히 인코딩한다는 사실이 드러났다. (아래 그림 참고) 이는 age, neuroticism, PTSD, 그리고 anxiety disorder scores 같은 예측 변수를 더 잘 예측한다는 뜻이다.
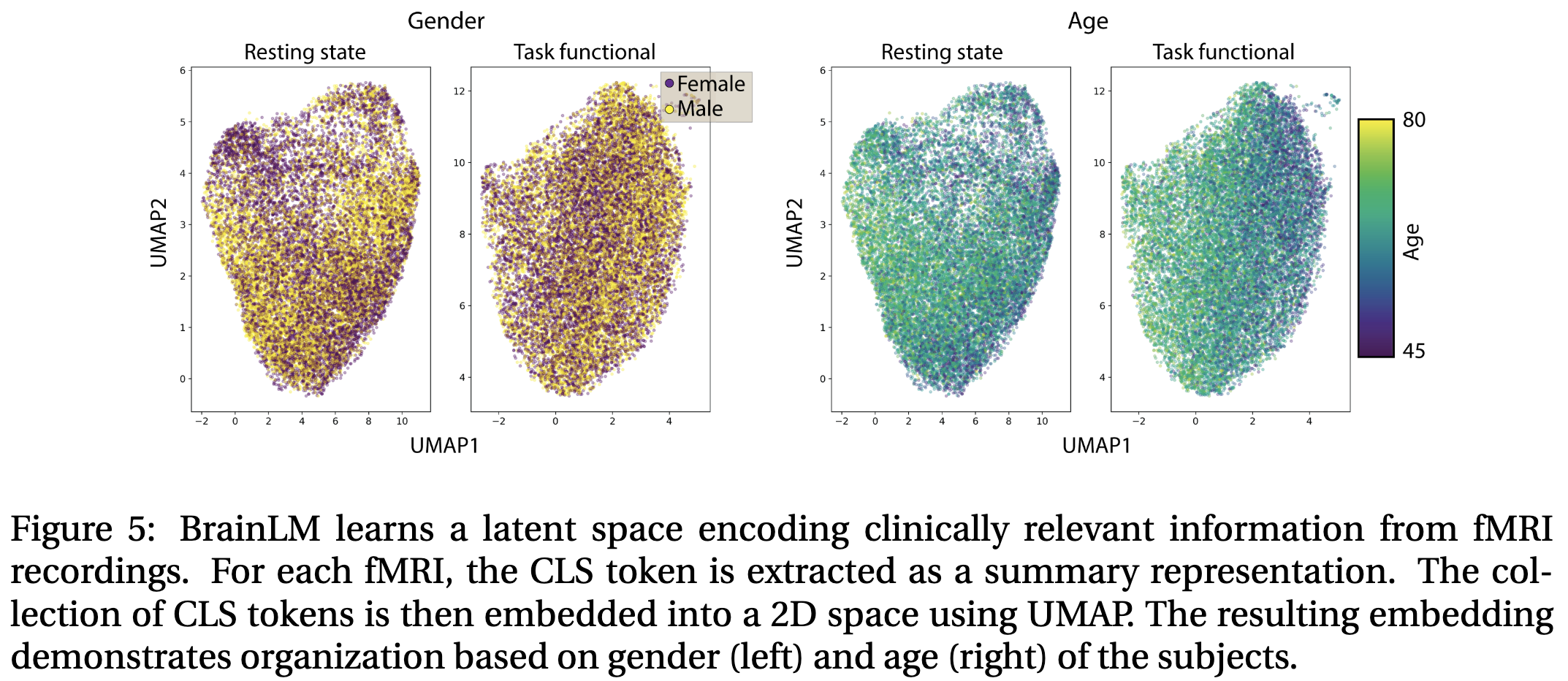
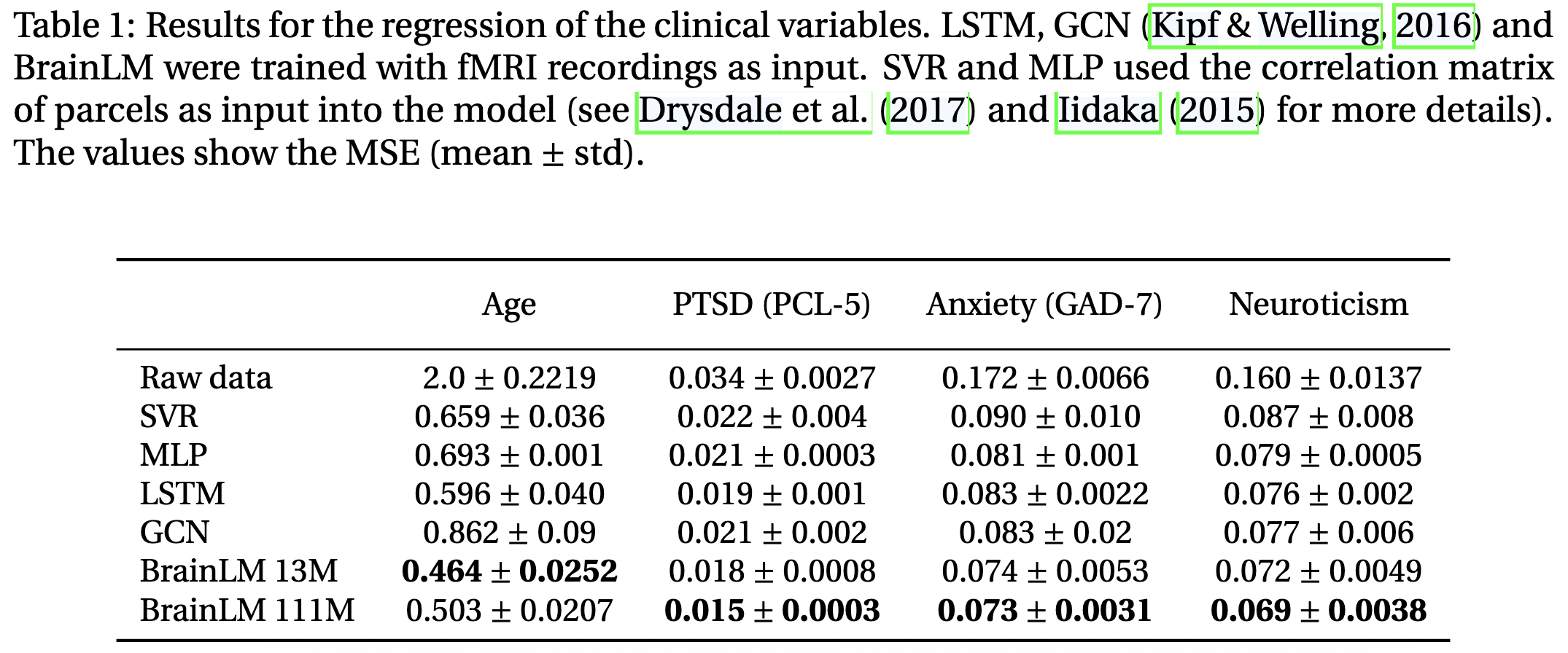
저자들은 다른 저명한 방법들과 이를 비교했다. 인상깊게도 BrainLM은 모든 임상 변수에서 일관성있게 더 나은 결과를 냈다. (아래 표 참고)
4.3. Prediction of Future Brain States
BrainLM이 시공간 역학을 잘 잡아내는지 검증하기 위해 저자들은 미래 뇌 상태를 예측하는 성능을 측정했다. UKB의 subset을 이용하여 미래 시점의 parcel의 활동을 예측하는 task를 수행할 수 있게 fine-tune했다. 180 timestep을 주고 나머지 20 timestep을 예측하도록 하여 LSTMs, NODE, non-pretrained BrainLM을 비교한다. 결과는 다음과 같다.
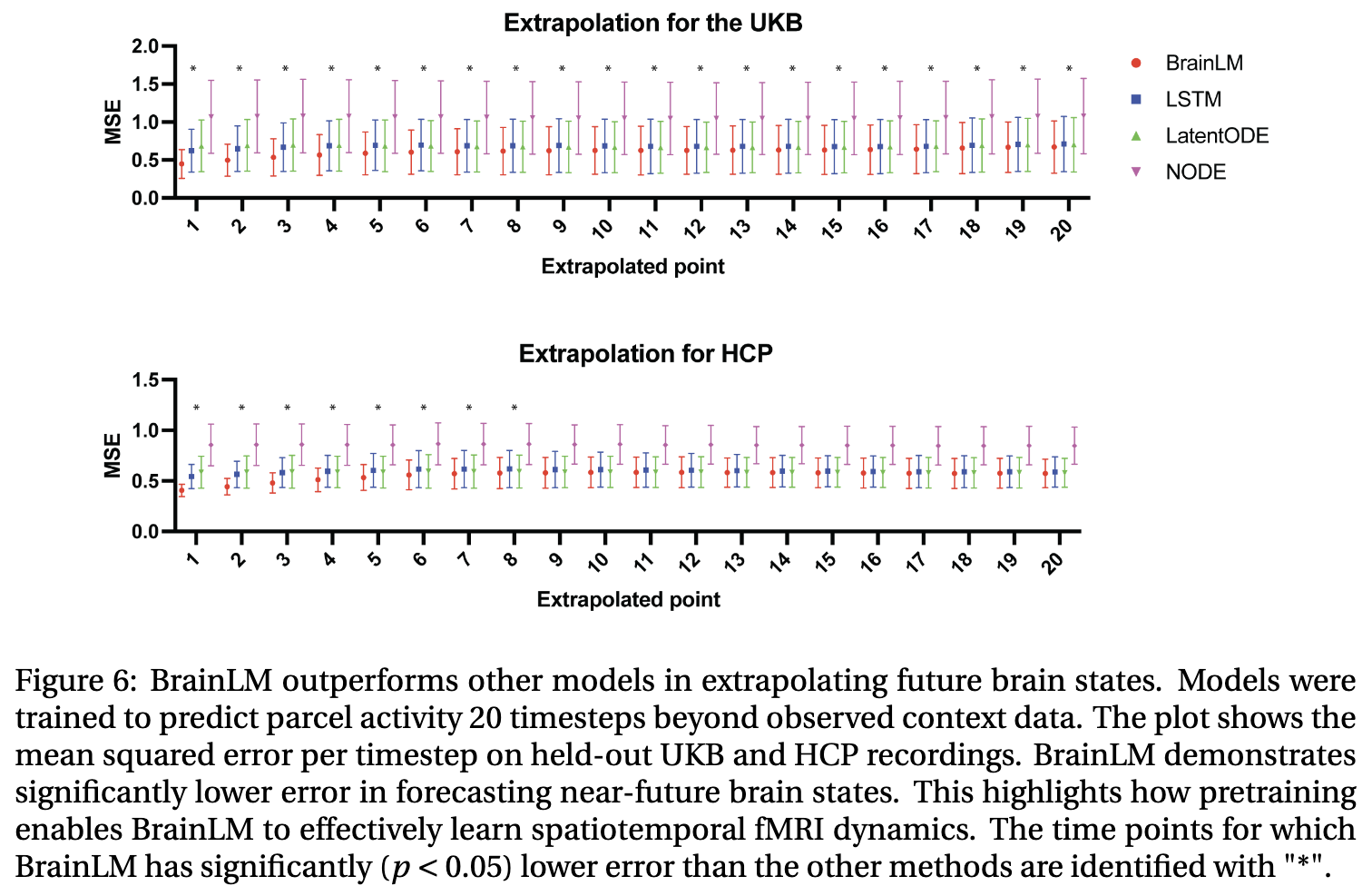
fine-tuned BrainLM이 UKB와 HCP 모두에서 성능이 좋았다. 이는 BrainLM이 fMRI의 역학을 직관적으로 파악하는 robust한 기능을 highlight한다.
4.4. Interpretability via Attention analysis
BrainLM의 중요한 특징은 interpretability이다. self-attention weight를 시각화 함으로 모델 내부 representation에 대한 깊은 통찰을 얻을 수 있다. 각각의 parcel에 할당된 fMRI recordings의 cls 토큰을 평균 내어 이를 계산한다.
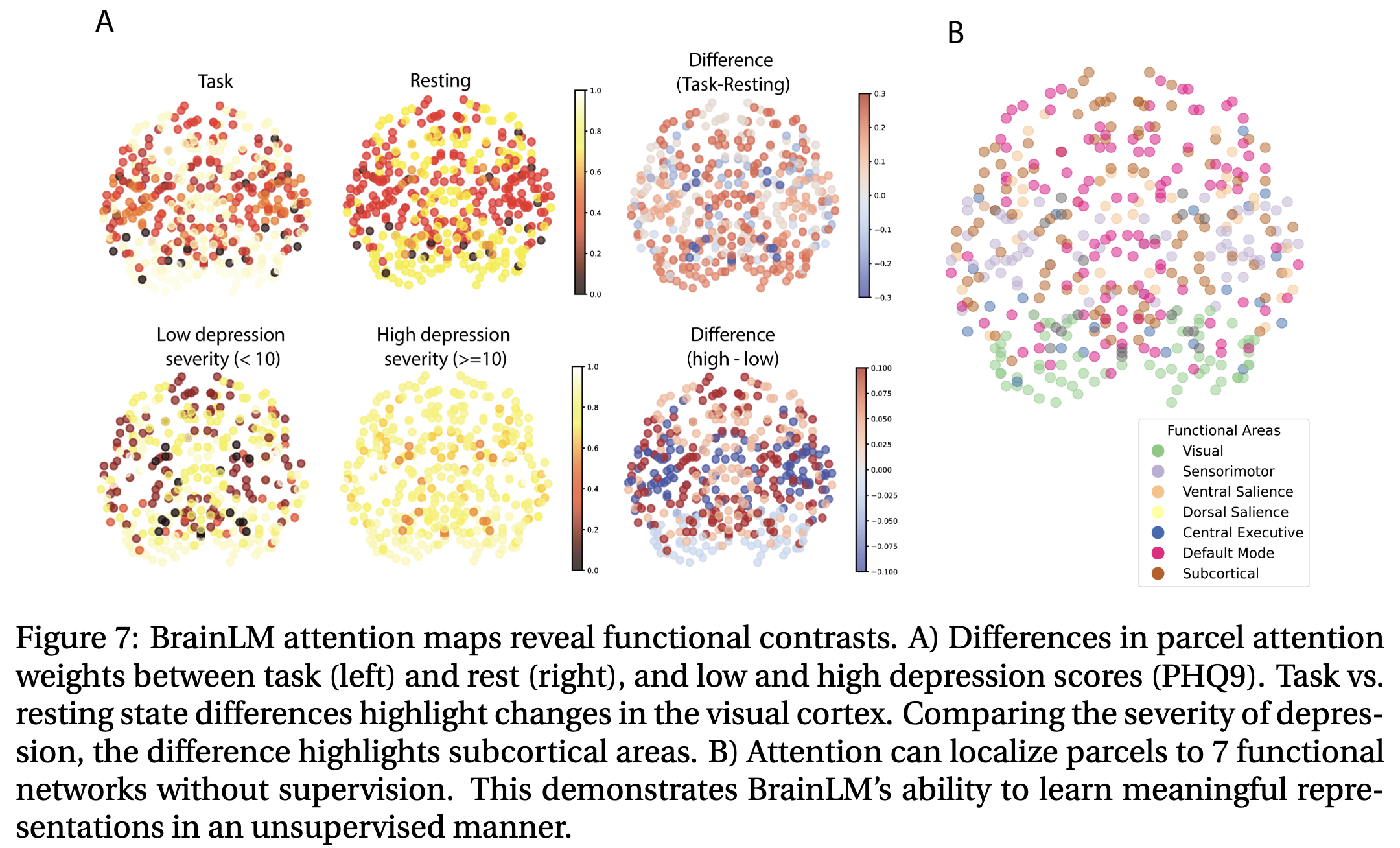
위 그림에서 볼 수 있듯이 rs와 비교했을때 task recordings는 visual cortex에 뚜렷한 초점을 가지는 것을 볼 수 있다. 이는 tasks 중 발생하는 시각적 자극과 잘 align 된다. 더 나아가 PHQ-9라는 우울증 임상 척도를 기준으로 중증 우울증 환자의 fMRI를 BrainLM이 인코딩할 때, frontal lobe(전두엽-감정 조절, 의사결정, 실행 기능 저하와 연관) 와 limbic system(변연계-감정 처리, 스트레스 반응, 보상 회로 이상과 연관) 영역에 attention이 집중되었다. BrainLM은 우울증 레이블을 직접 학습한 게 아님에도 임상적으로 의미 있는 뇌 영역을 자동으로 포착했다.
4.5. Functional Network Prediction
마지막으로 저자들은 BrainLM가 network-based supervision 없이도 parcels를 fMRI의 활성화 패턴만으로 intrinsic functional brain network로 segment할 수 있는지 검증했다. parcels를 7개의 functional categories로 나누고, 1,000 UKB recordings에서 각 parcel을 7개 중 하나로 k-NN classifier을 이용하여 분류하는 작업을 거쳤다. 결과는 다음과 같다.

BrainLM의 attention-driven approach가 다른 모델들을 압도 했으며 GCN이 가장 낮은 성능을 보였다. 이는 BrainLM가 label 없이 pre-training만으로 뇌의 functional topography를 내재적으로 학습하는 것을 의미한다.
5. Discussion
본 논문에서 BrainLM이라는 fMRI 분석을 위한 첫 foundation model을 도입했다. 6.7k시간의 풍부한 양의 brain activity recordings를 이용하여 modeling, predicting, interpreting 모두 좋은 성능을 보였다. BrainLM의 핵심은 fMRI recordings의 다른 분포의 데이터셋에서도 일반화된 representation이다. 또한 모델이 많은 파라미터를 가져도 잘 학습이 됐다.
BrainLM은 biomarker를 찾는 강력한 프레임워크를 제공한다. fine-tune을 통해 임상 변수와 psychiatric disorders를 예측할 수 있다. 이는 rs-fMRI 만으로 비침습적인 인지 건강 평가를 가능하게 한다. 마지막으로 network-based supervision 없이도 뇌의 intrinsic functional connectivity map을 바로 구분할 수 있었다.
개인적인 생각
- 본 논문은 fMRI 분석을 위한 첫 foundation model이다. 예측 성능뿐 아니라 attention map을 이용한 해석 가능성과 functional network prediction을 하는 것은 매우 놀라웠다.
- baseline model이 다소 예전 모델들이지만, 괄목할 만한 성능을 냈다.
- 도메인을 넘어선 self-supervised learning에서 masking approach의 강력함을 다시금 깨달았다. 이는 robust하고 generalized representation을 만들며, 모델 파라미터에 갯수에 구애받지 않는 아주 좋은 전략인 것 같다.
- 아직 fMRI 관련 논문을 찾는 단계라 모르는 부분이 많았는데, 학습 과정과 전처리 과정이 잘 나와있어서 좋았다.