[논문리뷰] Training ViT with Limited Data for Alzheimer’s Disease Classification: an Empirical Study
MICCAI 2024 [Paper] [Github]
Kunanbayev Kassymzhomart, Shen Vyacheslav, Kim Dae-Shik
23 Oct 2024
Introduction
지난 10년간의 CNN 모델의 시대는 이미 ViT에 의해서 끝났다. 비록 CNN은 locality나 spatial invariance 같은 vision specific inductive bias를 가지고 있지만 좀 더 전역적인 Long-range global dependencies를 수용하는 것에 실패했다. 이는 MRI를 포함한 의료 영상 분석에 제일 중요한 것이다. 더 나아가, 3D CNN모델은 ViT보다 계산 자원이 더 많이 요구된다. Long-range global dependencies를 수용할 수 있으며 계산 효율이 높은 ViT는 CNN이 쉽게 만들어내는 inductive bias를 만들기 위해 아직까지는 많은 양의 data가 필요하다는 한계가 남아있다. 이런 low-data regime을 해결하기 위해 많은 시도가 있었지만, 뇌 영상 응용 분야에서는 손에 꼽도록 적다. 따라서 알츠하이머 병(AD)와 같은 특정 질병과 관련된 구조적 뇌 MRI 데이터셋의 제한된 양 때문에 정확한 진단 도구의 개발이 저해된다. 많은 CNN 기반 연구가 놀라운 결과를 얻었지만, downsampling으로 인한 잠재적인 정보 손실이 초래된다. (ViT와 CNN을 결합하여 하이브리드로 학습한 방법도 있었다.) 본 논문에서는 plain ViT를 이용하여 제한된 양의 3D MRI를 학습하는 법을 제안한다. CNN feature를 활용하지 않는 것에 대한 잠재력을 검증을 위해 plain version을 사용하는 것에 집중한다.
Method
Training strategies
본 논문은 Masked AutoEncoder를 기반으로 하기 때문에 Model은 Encoder와 Decoder로 나뉜다. 우선 아래 그림에서 보이듯이 Encoder는 ViT-B을 사용한다. 이때 MRI가 3D 영상이기 때문에 3D input을 처리하도록 입력단을 구성한다.
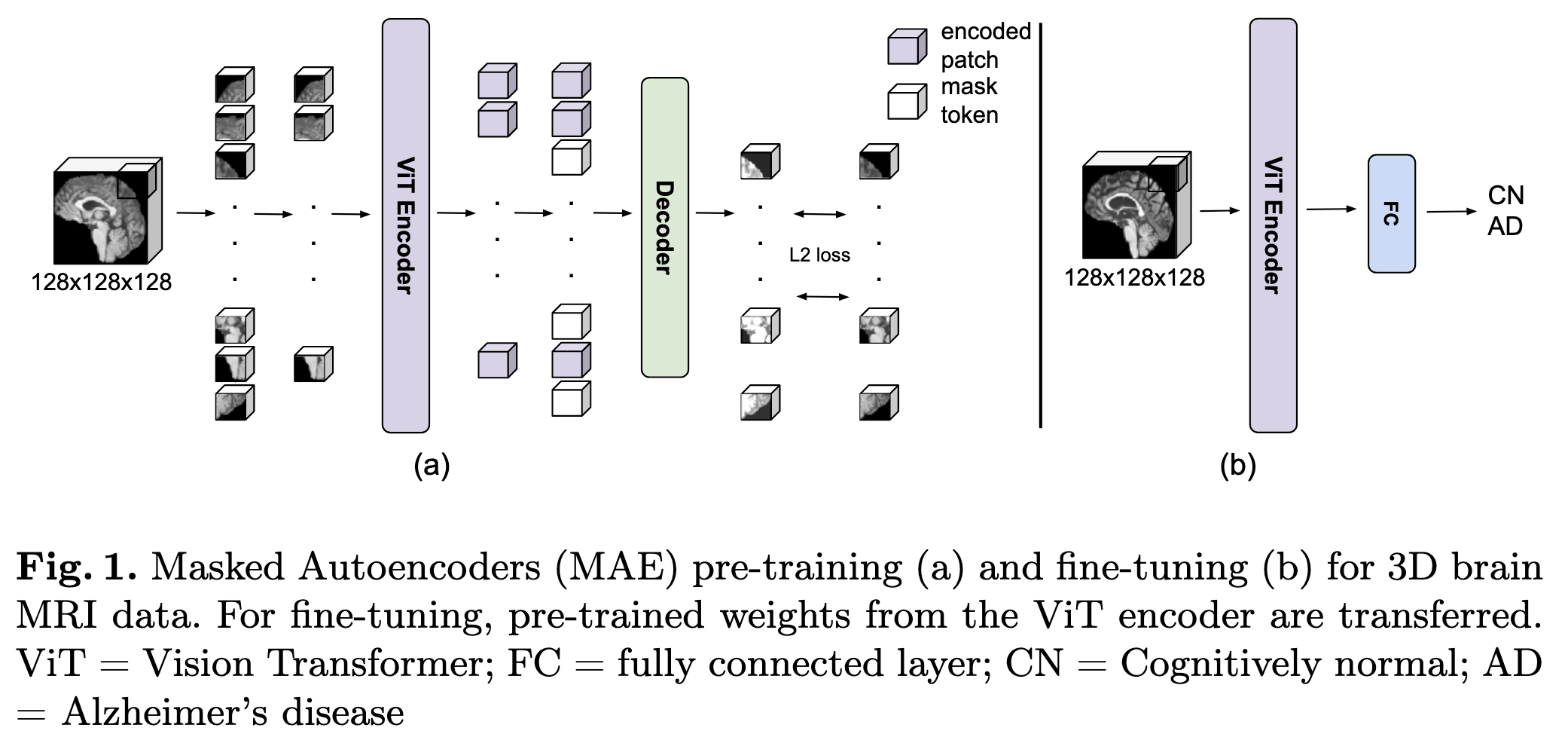
pre-training 단계는 딥러닝 모델을 성공적으로 개발하기 위한 방법이며, ViT에 inductive bias를 제공하는 방법이다. 나아가 질병과 관련한 dataset은 low-data regime인 경우가 많기 때문에 사용 가능한 의료 영상을 활용하여 self-supervised pre-training을 하는 것이 중요하다고 저자들은 말한다. 따라서 저자들은 AD나 치매와 관련없는 public MRI 데이터를 MAE 방식으로 pre-train에 사용했다. (참고: MAE는 마스킹을 통해 시공간 적으로 효율적인 학습을 하며 decoder가 encoder보다 더 작아도 괜찮다.) 첫번째로 3D MRI 이미지를 겹치지 않게 잘라서 fixed 3D position embedding(PE)을 붙인다. 다음에는 임의로 마스크를 씌우고 lightweight decoder로 영상을 복원하도록 한다. 이는 MAE의 학습 방식을 따른다. decoder로는 16 head 8 layer 576(3D 고려한 수)짜리 ViT를 사용한다(36.9M 파라미터).
Fine-tunning 단계에서는 pre-trained encoder에 classification head를 붙이고 학습 가능한 PE를 사용한다.
pre-train 단계에서 마스킹 비율을 25%, 50%, 75%로 3번 학습하여 각각 비교했으며, 데이터의 크기가 downstream task 성능에 미치는 영향과 여러 서로 성질이 다른 데이터셋을 조합한 결과 또한 살펴본다.
transformer 기반 모델은 pre-train 후에 적은 샘플만으로 downstream task에서 좋은 성능을 내왔다. 따라서 저자들은 ViT에서 일반화 성능을 확인하기 위해 데이터셋의 10%, 20%, 40%, 60%, 80%를 활용하여 fine-tune하는 실험도 했다.
Hyperparameters ablation으로 dropout과 attention dropout, drop path로 regulazation을 UNETR을 따라 augmentation도 실험했다.
마지막으로 DeiT의 성공에 힘입어 knowledge distillation도 실험했다.
Datasets
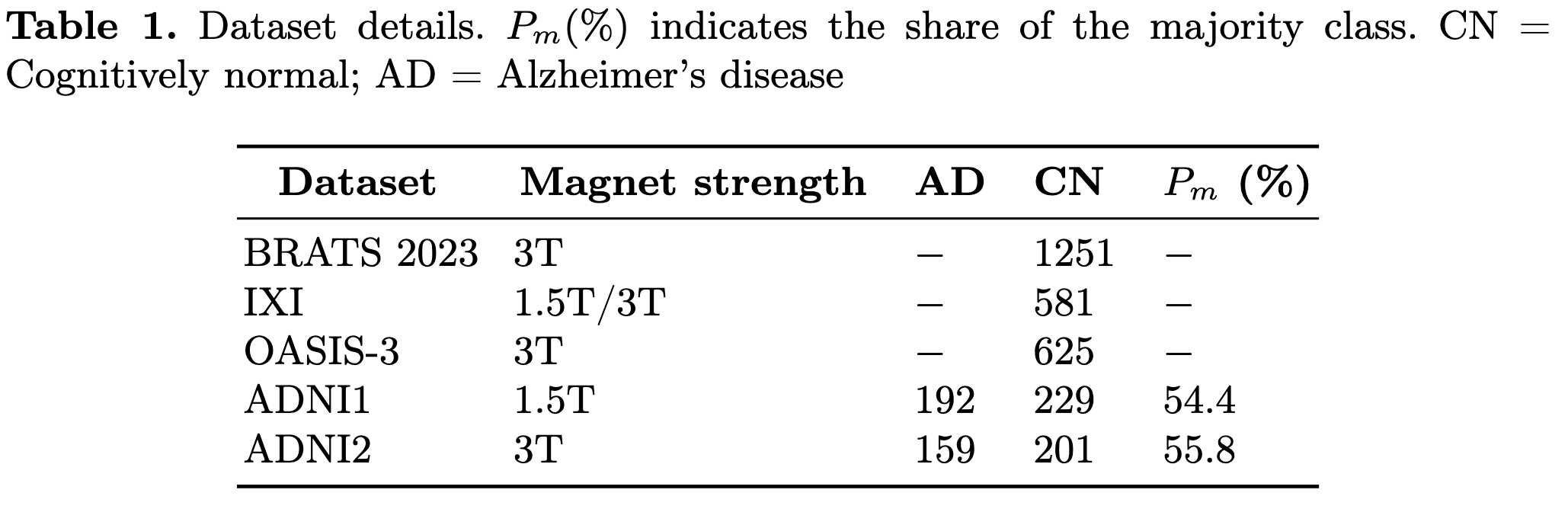
MAE pre-trian용 dataset으로 서로 다르고 공개됐으며 서로 성질이 다른 BRATS 2023, IXI, OASIS-3의 T1 weighted MRI를 사용한다. BRATS와 IXI는 AD, 치매와 무관하며 OASIS-3는 인지 저하의 다양한 단계의 이미지를 포함하지만, HD-BET를 이용하여 normal case만 사용한다. Fine-tuning datasets으로는 ADNI1, ADNI2를 사용했다. 모든 자세한 정보는 아래 표를 참고하면 된다.
Experimental setup
pre-processing
- resampling 1.75 × 1.75 × 1.75
- foreground crop
- resize: 128 × 128 × 128
- intensity normalization
pre-train
- optimizer: AdamW
- learning rate: 1e-4
- half-cycle cosine scheduler (40 epoch linear warmup)
- epochs: 1000
- batch size: 32
- random spatial crop
fine-tune
- learning rate: 1e-5
- cosine annealing scheduler
- loss: CE
- epochs: 50
- batch size: 4
- 4-fold cross validation(low-data regime에서 더 정확히 성능을 측정하기 위해)
- 모든 실험을 3번 반복하고 평균을 보고함.
Results and Discussion
참고: 앞으로 별 언급이 없는 한 75%의 마스킹 비율로 모든 데이터셋에서 pre-train한 실험에 관한 내용이다.
pre-training findings
- pre-training은 정확도를 높혀준다.
아래 표는 from scratch에서 학습한 결과와 MAE로 fine-tune한 결과를 비교하는 표다. 전반적으로 fine-tune한 결과가 정확도가 높았으며, 75%의 마스킹 비율로 pre-train을 했을때 성능이 가장 좋았다. 이는 선행 연구와 일치하는 결과이다. 그럼에도 저자들은 AD나 치매와 관련없는 데이터셋으로 학습을 했기 때문에 이 부분을 강조한다.
- Pre-training data size는 중요하며 서로 다른 데이터셋을 결합하는 것이 효과적이다.
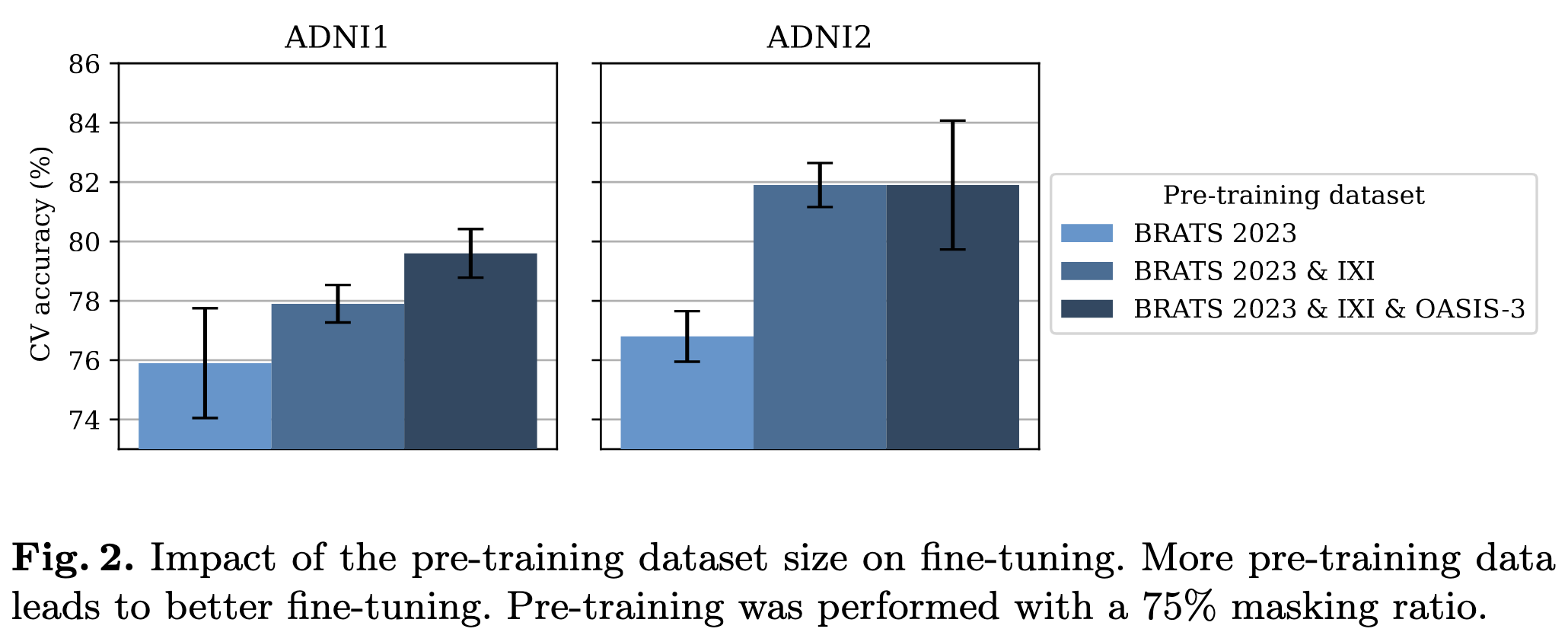
위 그림에서 볼 수 있듯이 서로 다른 데이터셋을 결합하여 많은 양으로 pre-train 했을때 성능이 좋았다. 이로 인해 많은 양의 데이터와 서로 성질이 다른 데이터셋을 결합하는 것이 정확도를 높이는 데에 있어 중요하며 여러 augmentation을 통해 성능을 높일 수 있을 것이라고 저자들은 예측한다.
- Pre-training은 극도로 적은 labeled dataset으로도 성공적인 학습을 할 수 있게 한다.
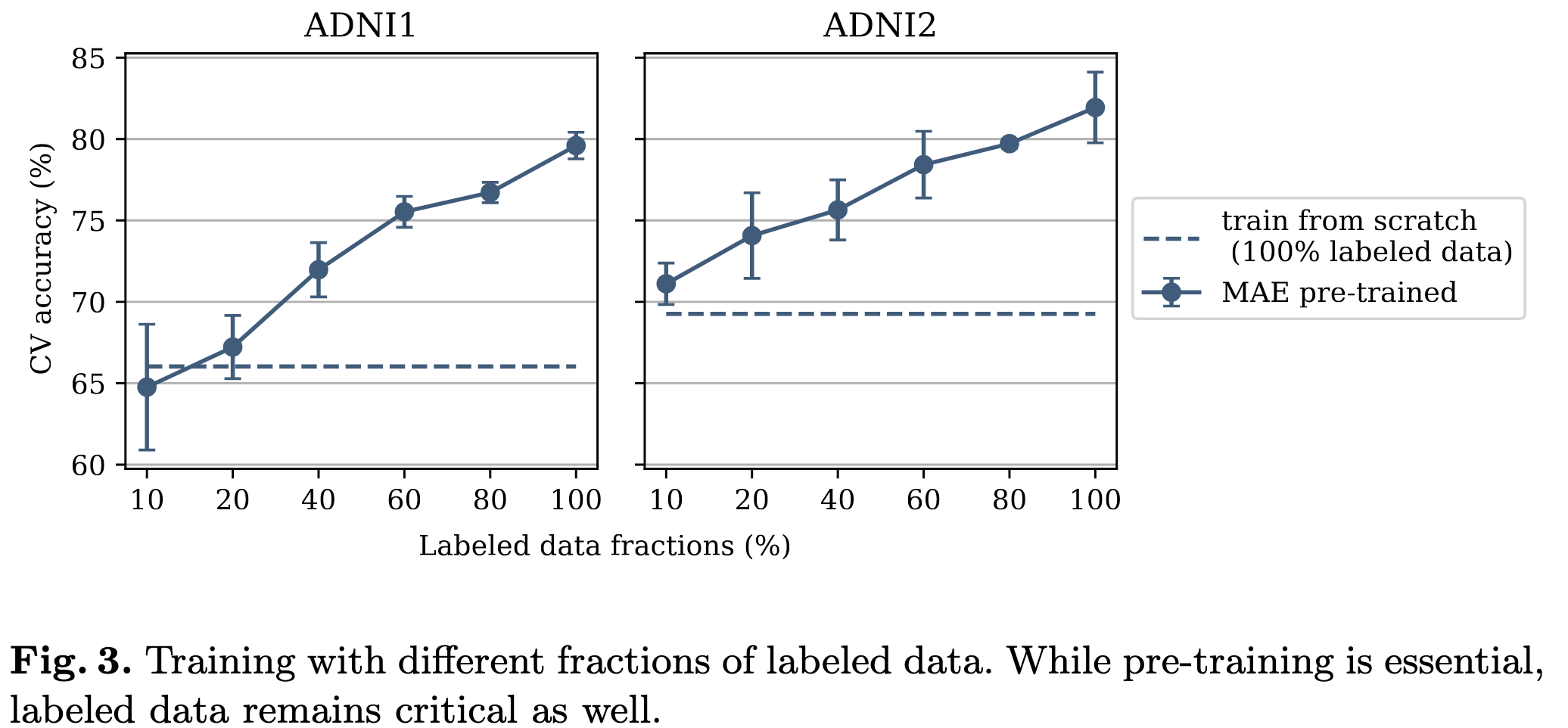
위 그림은 10~100%의 label dataset으로 학습시킨 결과이다. 일반적으로 20%가 넘어가면 from scratch보다 성능이 좋았다. 20%면 60개 정도의 샘플인데 이 양만으로도 충분히 더 좋은 성능을 낼 수 있는 것은 놀라운 결과이다. 저자들은 이를 통해 ViT는 low-data 시나리오에서 downstream task와 관계없는 데이터셋을 이용하여도 pre-training에 큰 이익이 있음을 시사한다. 그럼에도 불구하고, 더 나은 성능을 위하여 fine-tune dataset은 많을수록 좋다.
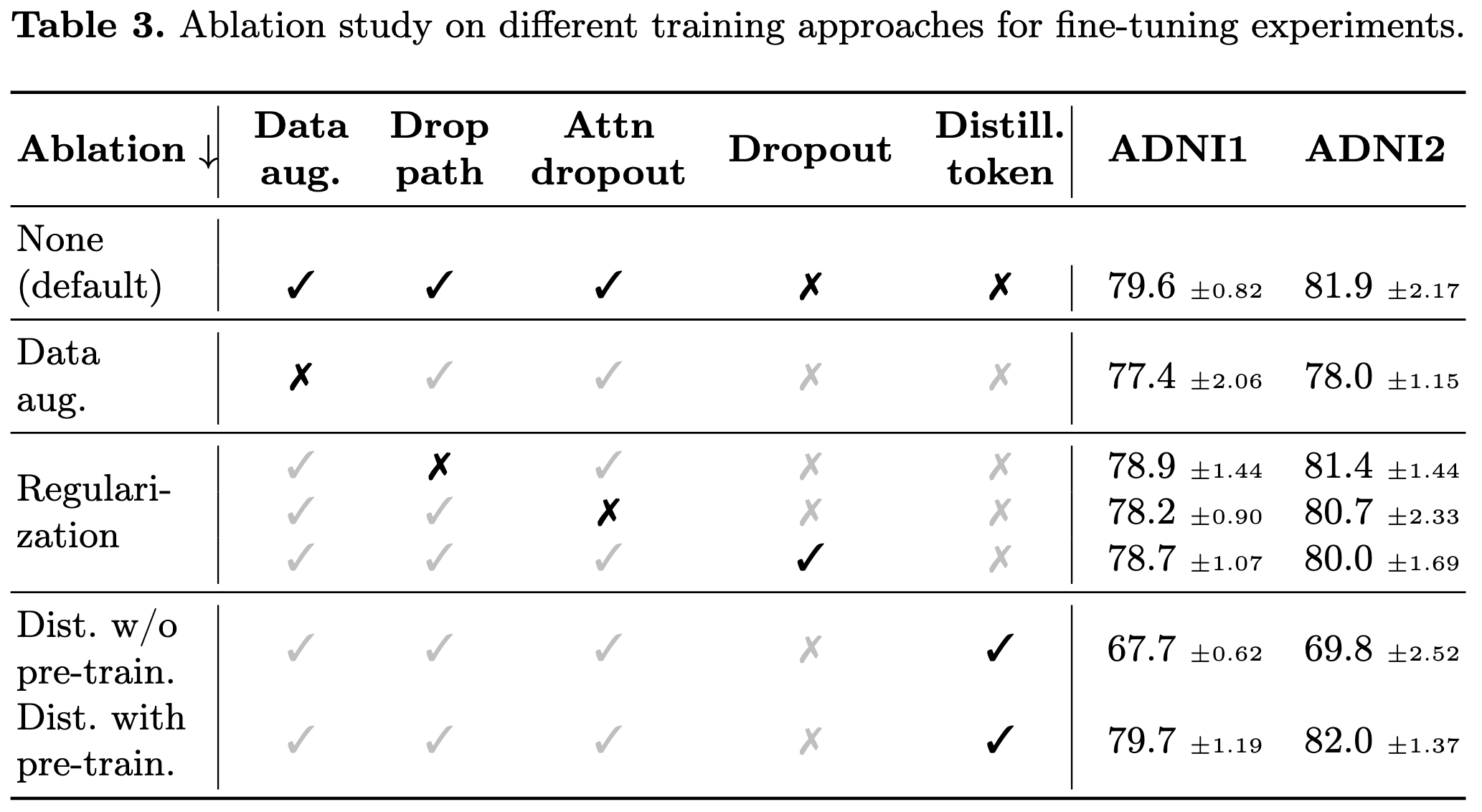
Ablation study
아래의 표는 ablation study의 결과이다. augmentation을 사용하면 3.4%의 성능 향상이 있었지만, regulazation을 사용했을때는 성능 향상을 확인할 수 없었다. 비슷한 결과는 “How to train your vit? data, augmentation, and regularization in vision transformers” 논문에서도 관측된 바가 있다. (훈련 데이터가 클 수록 오히려 규제가 성능 저하를 일으킴.)
knowledge distillation도 0.1%의 성능 향상이 있었으나 teacher model을 학습하기 위해 소모되는 GPU 메모리를 생각해볼때 큰 의미는 찾기 어려웠다.
Conclusion
본 논문을 통해 저자는 low-data regime인 AD에서 ViT를 전략적으로 학습하는 방법을 조사했다. low-data 시나리오에서 pre-train은 fine-tune accuracy를 높이는데 크게 기여했으며 downstream task와 관련없는 데이터셋으로도 충분히 좋은 성능을 낼 수 있었다. 추가적으로 pre-train dataset의 크기가 여전히 중요하며 이때 서로 성질이 다른 데이터셋이어도 괜찮고 오히려 이익이 있음을 확인했다. 마지막으로 ViT를 이용하여 fine-tune 정확도를 높이는데 유용한 최적의 훈련 레시피를 제공했다. 저자는 이 방법이 다양한 의료 데이터셋에서 최적화된 모델을 학습하는데 유용할 것이라고 말한다.
limitation으로는, 하나의 pre-train 방식으로 하나의 downstream task로만 실험이 된 것이 있으며 저자들은 contrastive based method 로도 실험을 할 것이며 더 많은 task로 확장할 것이라는 언급과 함께 글을 마무리 짓는다.
개인적인 생각
이 논문을 통해 pre-train의 중요성을 다시금 느꼈으며, MAE의 강력함을 느꼈고, 서로 다른 데이터셋을 결합하는 것의 의미를 깨달았다. 해당 논문이 제시한 레시피가 극단적인 LT 상황에서도 유용할지 궁금하다. 이 부분에 대한 논문들을 찾아서 빠르게 공부해봐야겠다.