[논문리뷰] Brain Network Transformer
NeurIPS 2022 [Paper] [GitHub]
Xuan Kan, Wei Dai, Hejie Cui, Zilong Zhang, Ying Guo, Carl Yang 15 Oct 2022
1. Introduction
Brain network analysis는 신경 과학자들에게 사람의 뇌 구조 이해와 임상 결과 예측을 위한 흥미로운 연구이다. 다양한 모달 중 fMRI가 뇌 네트워크 구조를 위해 주로 사용된다. fMRI의 노드는 atlas 기반의 ROIs로 정의되고 각 노드간 BOLD 신호의 상관관계로 엣지를 정의한다. 연구자들은 action, language, and vision 같은 cognitive-related tasks가 일어날때 특정 영역이 동시에 활성화되거나 비활성화 되는 것을 관측해왔다. 이런 패턴을 바탕으로 brain regions을 다양한 기능적 모듈로 분류하여 질병을 분석하여 진단, 진행 이해 및 치료에 사용할 수 있다.
Transfer의 여러 분야에서의 성공을 해왔고 그 중 GAT라는 모델이 처음으로 GNNs의 영역에 적용되었다. 그러나 이는 이웃 노드의 local 구조만 고려하였다. Graph Transformer는 edge information을 attention mechanism에 집어넣었고 각 노드의 eigenvectors를 position embedding(PE)로 활용하였다. SAN은 eigenvalue와 eigenvectors를 동시에 고려하여 PE를 더 강화하고 attention을 local 구조에서 global 구조로 확장하였다. Graphomer는 독창적인 메커니즘으로 OGB Large-Scale Challenge에서 우승하였다.
그러나 brain networks는 기존 Graph Transformer 모델이 실용적이지 않은 독특한 특성이 여럿 있다.
- 주로 사용되는 방법이 ROIs 간의 BOLD 신호의 correlation이다. 이는 centrality, spatial 그리고 edge encoding 같은 디자인을 방해한다. 왜냐하면 각 노드들은 같은 차수를 가지고 모든 노드간 single hop으로 연결되어 있기 때문이다.
- 기존 Graph transformer models는 eigenvalue와 eigenvectors를 주로 PE에 사용한다. 왜냐하면 그들은 각 노드의 identity와 positional information을 제공하기 때문이다. 그러나 brain network에서는, brain network adjacency matrix의 각 노드의 해당 행으로 정의되는 connection profile이 가장 효과적인 node feature로 인식된다. 이 node feature는 구조적, 위치적 정보 둘 다 자연스럽게 인코딩한다. 이는 앞서 설명한 PE 디자인이 중복으로 여겨 진다.
- Scalability도 중요하다. 보통은 노드와 엣지의 수가 50과 2500개 미만인데, brain network는 atlas에 따라 100~400 개의 노드를 가지고 이는 최대 160k개의 엣지가 생긴다. 그러므로 현존하는 Graph transformer model으로 모든 엣지의 기능 생성과 같은 작업이 불가능하지 않더라도 시간이 많이 걸릴 수 있다.
본 논문에서는 brain network analysis를 위해 brain network의 독특한 특성을 transformer-based moedl의 힘으로 완전히 해방하는 BRAIN NETWORK TRANSFORMER (BRAINNETTF, 다른 논무에서는 주로 BNT로 불림)을 제안한다. 특히, 기존 GNN에서의 발견을 통해 connection profiles의 초기 node feature를 효과적으로 초기화하는 방법을 제안한다.
한 단계 나아가서 brain network analysis에 GNNs를 사용할 때는 학습된 node embedding을 기반으로 readout function을 통해 graph-level embedding을 생성해야 한다. brain network의 특성상 동일한 기능적 모듈에 속하는 노드들은 다양한 자극에 대한 활성화 및 비활성화 반응에서 유사한 행동 양식을 공유하는 경우가 많다. 이를 위해 ORTHONORMAL CLUSTERING READOUT을 설계하여 노드들의 cluster에서 graph-level embedding을 pooling한다.
마지막으로 공개 데이터셋의 부족은 brain network analysis에서 무시할 수 없는 과제이다. 예를 들어 ABIDE는 별도의 접근 허가 없이 fMRI를 완전히 사용할 수 있지만 17개의 기관에서 서로 다른 스캐너와 파라미터를 사용하여 획득된다. 이러한 inter-site variability는 실질적으로 의미 있는 집단 간 차이를 가려버리며 이로 인해 학습시 불안정성 증가 및 검증/테스트 셋과의 유의미한 격차로 나타난다. 이를 해결하기 위해 stratified sampling을 제안하고 표준화 할 것을 제안한다.
2 Background and Related Work
해당 섹션에서는 배경과 관련 연구를 설명한다. 본문에서는 다루지 않는다.
3 BRAIN NETWORK TRANSFORMER
3.1 Problem Definition
brain network analysis에서 brain network: $X \in \mathbb{R}^{V \times V} $ where $V$는 node (ROIs)의 수 이며 주로 성, 질병의 유무, brain subject의 특징을 예측하는 것이 모델의 주 목표이다. BNT의 전반적인 프레임워크는 아래 그림과 같다. $L$개의 MHSA layer와 graph pooling operator OCREAD로 두개의 main component로 이루어져있다.
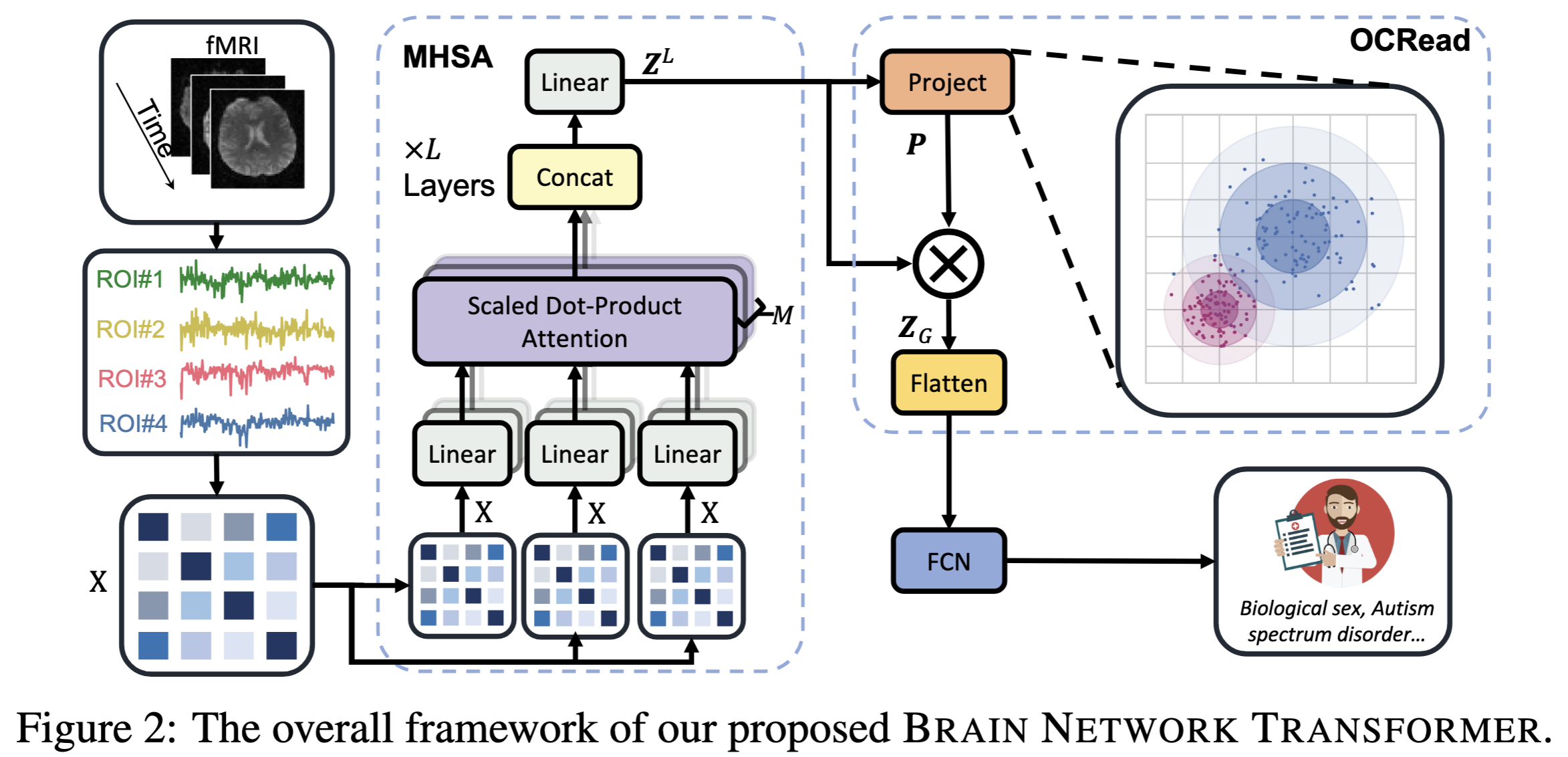
MHSA에서 non-linear mapping $X \rarr Z^L \in \mathbb{R}^{V \times V}$을 통해 attention-enhanced node features $Z^L$을 학습한다. OCREAD은 enhanced node embeddings $Z^L$을 graph-level embeddings $Z_G \in \mathbb{R}^{K \times V}$ 로 압축한다. $K$는 hyperparam인 number of clusters이다. $Z_G$는 flatten 후 MLP를 통과하여 graph-level prediction을 한다. 모든 학습 과정은 CE를 통한 supervised learning을 통해 이루어진다.
3.2 Multi-Head Self-Attention Module (MHSA)
brain network에 적합한 Transformer-based model을 개발하기 위해 PE와 attention mechanism이라는 두가지 기초 디자인에 대한 재고가 필요하다. 현존하는 모델은 eigendecomposition을 통해 주로 위치 정보를 인코딩하지만, 이는 dense한 brain network에서 비용이 많이 들고 edge의 존재가 유익하지 않다.
brain networks의 ROI 노드는 이미 필요한 위치 정보를 가지고 있으므로 eigendecomposition을 통한 position encoding은 중복이다. 기존 연구에서 connection profile $X_i$을 통한 분석이 항상 eigenvectors를 이용한 방법보다 좋은 성능을 보였다. 또한 이전 연구에서 edge weight를 attention score에 통합하면 완전 그래프에서 attention의 효과를 크게 저하시킬 수 있음을 경험적으로 입증하였다. 또한 brain network는 edge가 매우 많기 때문에 edge-wise embedding을 생성하는 것이 계산적으로 감당하기 어렵다. 또한 이 케이스에서 모든 엣지가 단순히 존재하기 때문에 존재 여부 자체도 attention score 계산에 유용한 정보를 제공하지 않는다.
이러한 관점에서 BNT는
- connection profile을 초기 node feature로 삼고 PE를 없앤다.
- edge weight나 상대 위치 정보를를 사용하지 않는 바닐라 pair-wise mechanism을 사용한다.
$Z^L = \text{MHSA}(X) \in \mathbb{R}^{V \times V}$를 생성하는 $L$-Layer non-linear mapping module인 MHSA 수식은 다음과 같다. 각 레이어 $l$에 대하여 출력 $Z^l$은 다음과 같이 얻어진다.
\[\begin{equation} Z^l = \left( \Big\|_{m=1}^{M} h^{l,m} \right) W^l_Oh^{l,m} = \text{Softmax} \left( \frac{W^{l,m}_Q Z^{l-1} \left( W^{l,m}_K Z^{l-1} \right)^\top} {\sqrt{d^{l,m}_K}} \right) W^{l,m}_V Z^{l-1} \end{equation}\]여기서 $Z^0 = X$, ∥는 concatenation 연산자, M은 헤드 수, l은 레이어 인덱스, $W^l_O,\ W^{l,m}_Q,\ W^{l,m}_K,\ W^{l,m}_V$는 학습 가능한 파라미터, $d^{l,m}_K$ 는 $W^{l,m}_K$ 의 첫 번째 차원이다.
3.3 ORTHONORMAL CLUSTERING READOUT (OCREAD)
graph-level representation을 학습하는 readout function은 brain network analysis를 위해 필수적이다. Mean, Sum, Max가 주로 사용된다. 그러나 현존하는 방법 중 어느 것도 fig1(a)에 표시된 것 처럼 brain network의 동일한 기능 모듈의 노드가 유사한 동작과 clustering representation을 갖는 경향이 있는 속성을 사용하지 않는다.
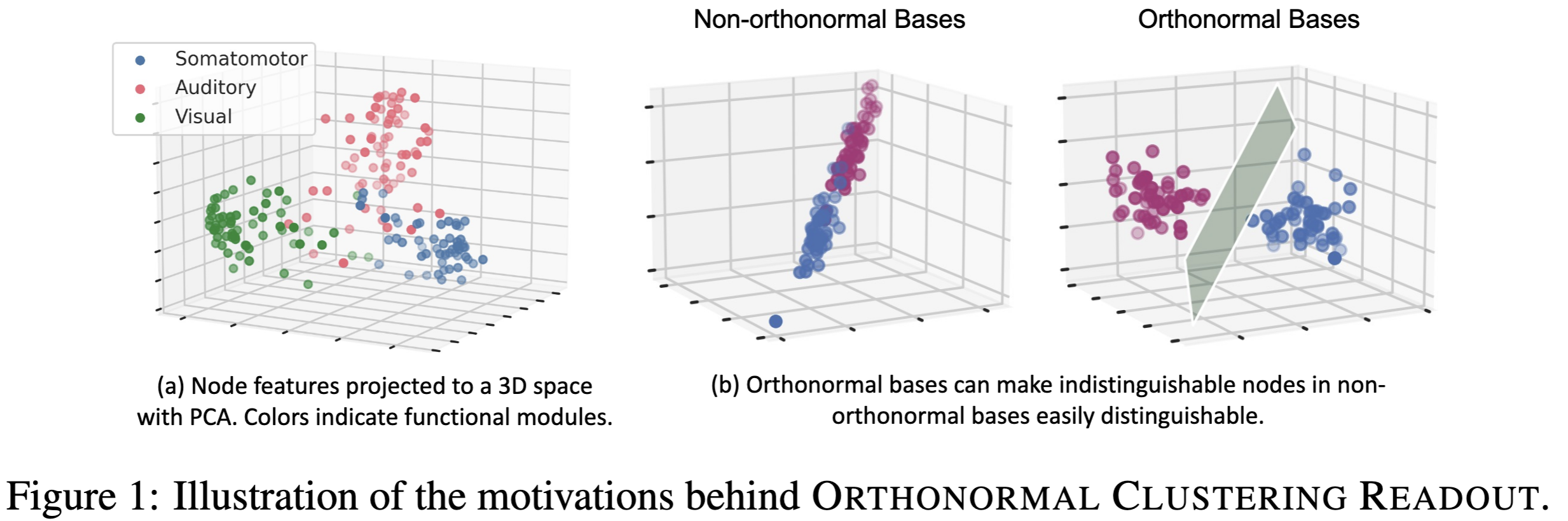
이를 해결하기 위해 ROIs긴 modular-level similarities의 이점을 활용하는 novel readout function을 제안한다.
$V$ 차원을 가진 $K$ 개의 cluster center $E \in \mathbb{R}^{K \times V}$ 가 주어졌을때 Softmax projection operator가 노드 $i$를 cluster $k$로 할당하는 probability $P_{ik}$를 계산하는 함수로 사용된다.
\[\begin{equation} P_{ik} = \frac{e^{\langle Z^L_{i\cdot},\, E_{k\cdot} \rangle}}{\sum_{k'}^{K} e^{\langle Z^L_{i\cdot},\, E_{k'\cdot} \rangle}}, \end{equation}\]soft assignment가 계산된 이후로 $Z^L$은 soft cluster information의 가이드를 받아 graph-level embedding $Z_G$로 집약된다. $Z_G = P^TZ^L$ 그러나 GT 없이 node embedding과 cluster를 학습하는 것은 어렵다. 따라서 클러스터 센터 초기화가 매우 중요하다. 이를 해결하기 위해 Fig1(b)에서의 관측을 활용한다. 이는 orthonormal(직교) embedding이 brain network내에서 node clustering을 향상시키는 것이다.
이 부분은 완전히 이해하지 못했다. 논문 본문에 이론적 정의가 잘 나와 있으니 참고하면 될 것 같다.
3.4 Generalizing OCREAD to Other Graph Tasks and Domains
본 논문에서 OCREAD는 FC based brain network를 이용하였다. 그러나 이에 국한되지 않고 Structural connectivities(SC)등에도 사용가능하며 protein-protein interaction networks나 유전자 발현 network에서도 사용가능하다.
4 Experiments
저자들은 다음 세가지 RQ에 대한 검증을 위주로 실험했다.
RQ1. How does BRAINNETTF perform compared with state-of-the-art models of various types? (SOTA 급인지?)
RQ2. How does our proposed OCREAD module perform with different model choices? (OCREAD 모듈은 다양한 모델 선택에서 어떻게 작동하는지?)
RQ3. Does the learned model of BRAINNETTF exhibit consistency with existing neuroscience knowledge and suggest reasonable explainability? (BNT가 현존하는 neuroscience knowledge와 일관성있고 함리적인 설명 가능성을 제안하는지?)
4.1 Experimental Settings
Dataset:
- ABIDE
- #: 1009 subjects
- 자폐: 516 subjects
- atals:Craddock 200
- network 바로 다운 가능
- multi-site problem을 stratified sampling로 해결
- ABCD
- #: 7901 subjects
- 여자: 3961 subjects
- atals: HCP 360 ROI
Metrics는 두 데이터셋 모두 binary classification이므로 AUROC를 사용했으며 임상 적용성을 위해 Sensitivity와 Specificity까지 3가지를 5 random seed에 평균과 표준편차를 보고한다. Model의 헤드는 4개 레이어는 2개를 사용했으면 7:1:2 split을 활용한다. Adam으로 1e-4의 초기 learning rate를 사용한다. weight decay는 1e-4를 사용하며, batch size는 64로 설정됐다. 200 epoch동안 AUROC가 가장 좋은 모델을 테스트에 사용했다.
4.2 Performance Analysis (RQ1)
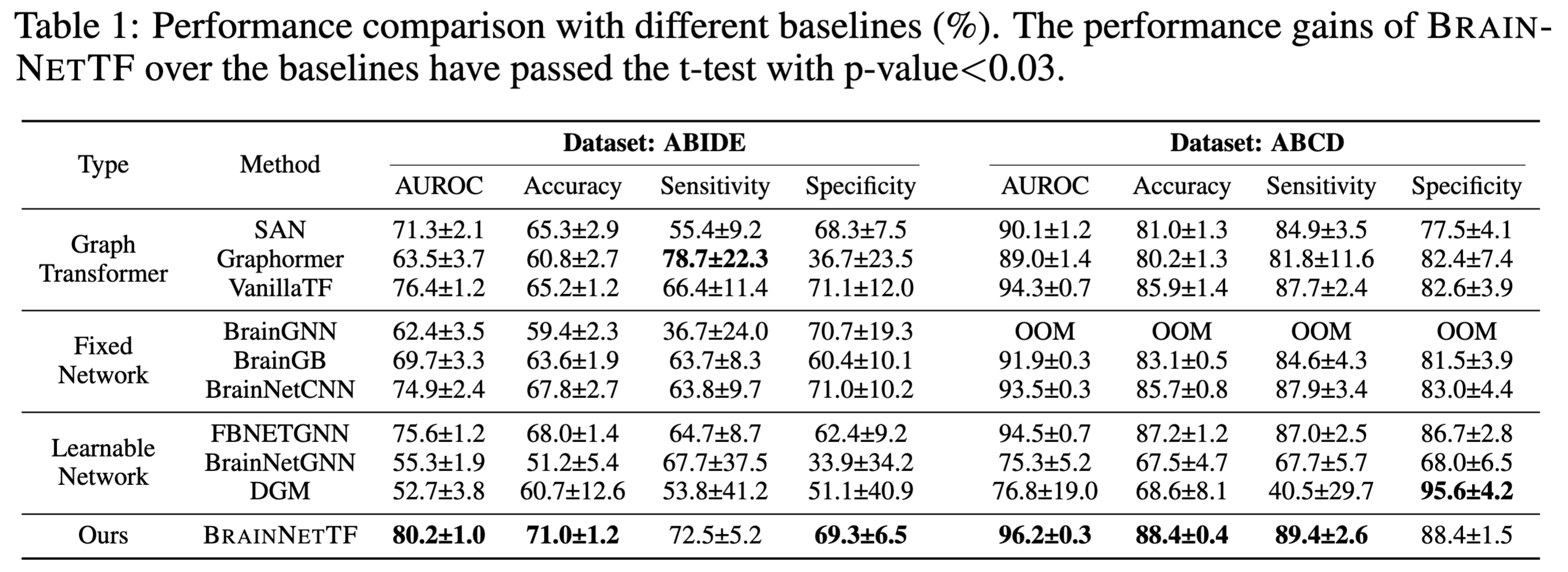
(a) BNT vs other graph transformers
위 표를 보면 알 수 있지만 VanillaTF가 다른 비교군을 AUROC 측면에서 이겼다. 저자들은 이를 brain network의 특성 때문이라고 분석했다. 이는
(b) BRAINNETTF vs. neural network models on fixed brain networks
BrainGNN, BrainGB 및 BrainnetCNN 등의 NN 기반 모델보다 더 좋은 성능을 보였다.
(c) BRAINNETTF vs. neural network models on learnable brain networks
learnable graph를 사용한 경우에도 더 좋은 성능을 보였다.
4.3 Ablation Studies on the OCREAD Module (RQ2)
4.3.1 OCREAD with varying readout functions
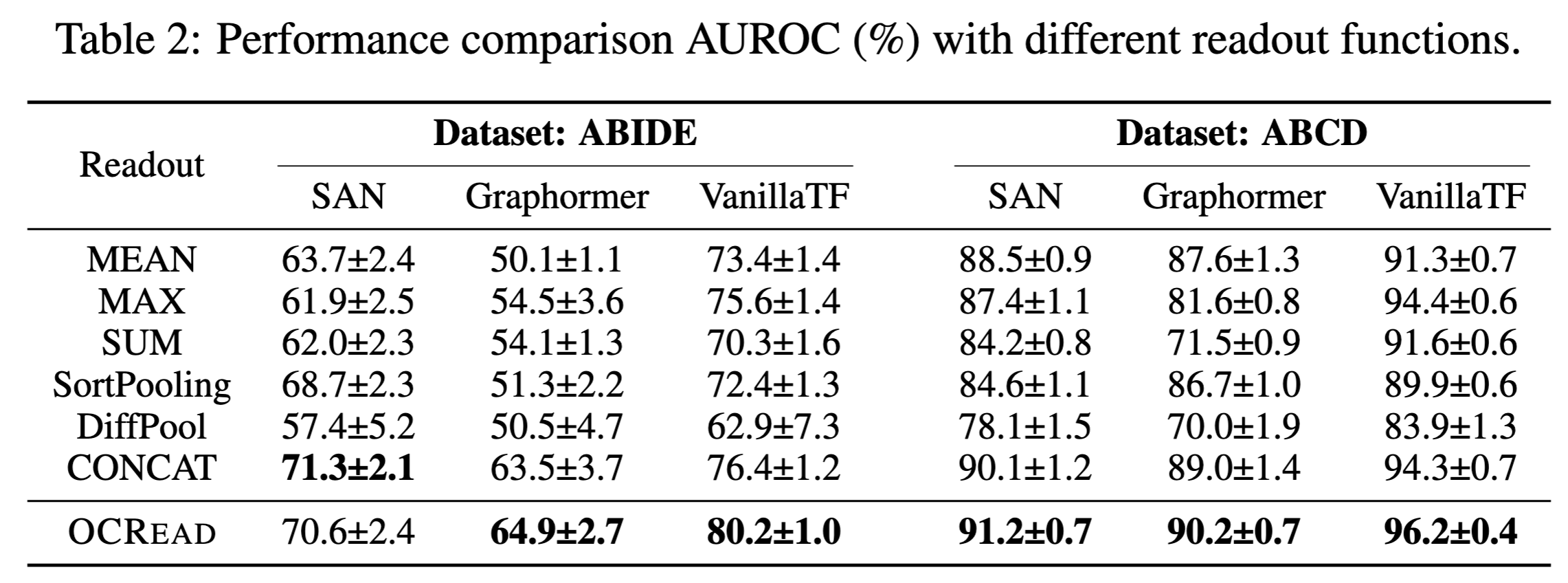
아래 표는 SAN, Graphormer and VanillaTF에 대하여 다양한 readout function과 본 논문에서 제안된 OCREAD를 비교한 표이다. 전반적으로 OCREAD가 가장 효과적인 readout function이었으며 다양한 transformer 아키텍처의 예측 성능을 높혀주었다.
4.3.2 OCREAD with varying cluster initializations
OCREAD의 설계가 BNT의 성능에 어떻게 영향을 미치는지 추가로 입증하기 위해 cluster center 초기화 방법과 cluster $K$의 수를 어떻게 선택하는지 이 섹션에서 논의한다. Random, Learnable, Orthonormal 세가지로 초기화 방법을 비교했으며 2, 3, 4, 5, 10, 50, 100로 $K$를 비교한다. fig3(a)가 이의 결과이다.
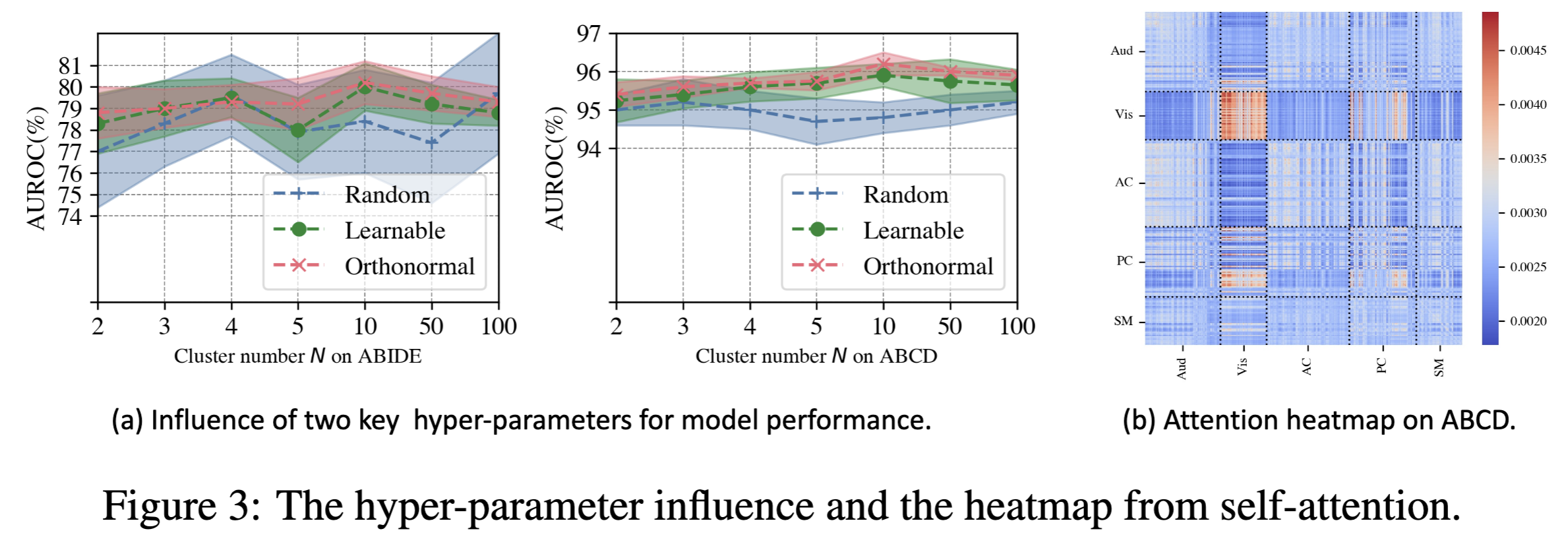
결과에 따르면 최적의 $K$의 수는 상대적으로 작다. 이는 적은 계산량으로 이끌며 일반적인 functional module의 수가 25개 미만인 것과 일치한다. 충분히 큰 $K$에서는 세가지 방법이 비슷한 성능을 보이나 적은 $K$에서 제안된 orthonormal 방법이 가장 안정적으로 성능을 낸다. OCREAD의 std가 가장 작은 것도 알아두면 좋다.
4.4 In-depth Analysis of Attention Scores and Cluster Assignments (RQ3)
fig3(b)는 ABCD 테스트셋에서 MHSA 첫 레이어의 평균 self-attention score이다. 이는 학습된 attention score가 available labels 기반의 functional modules의 구분과 잘 일치하여 transformer 모델의 효율성과 설명 가능성을 보여준다. ABIDE는 label을 제공하지 않기 때문에 시각화하지 못했다.
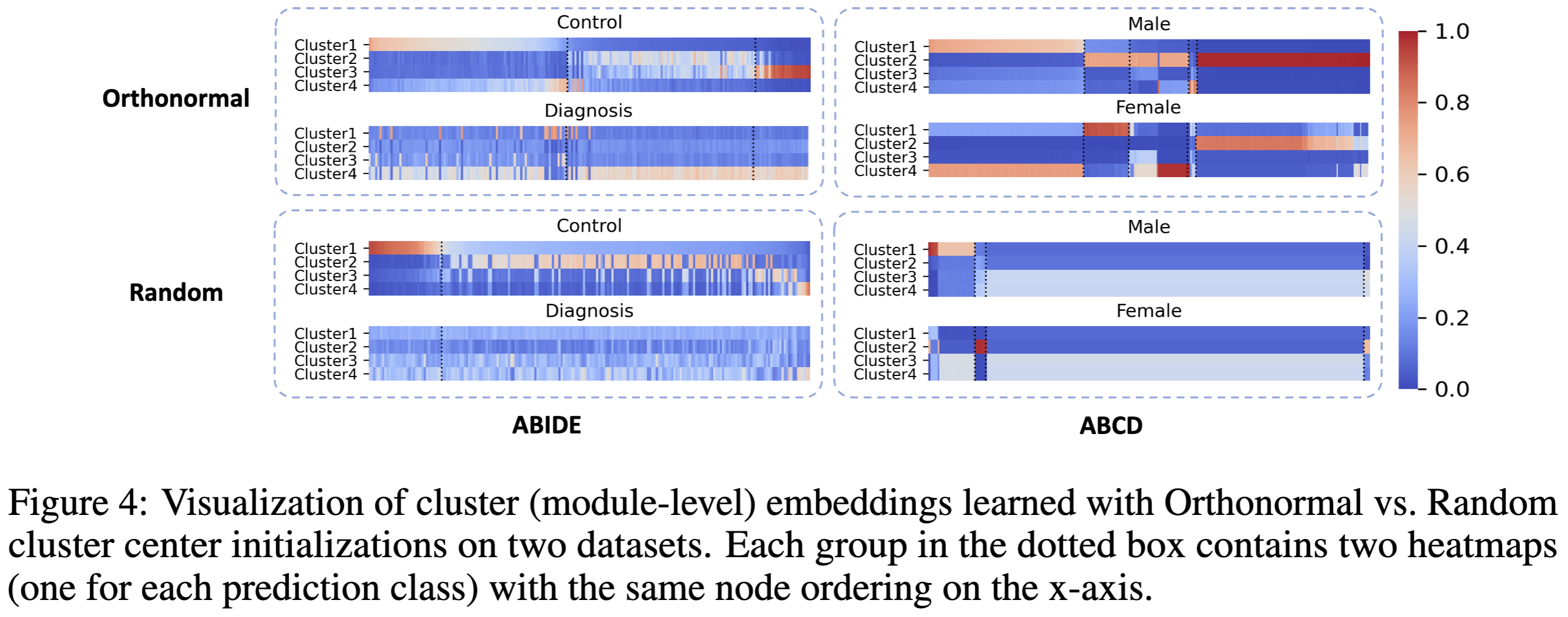
아래 그림은 두 가지 초기화 방법을 사용하여 OCREAD의 노드에 대한 cluster soft assignment 결과 $P$를 보여준다. orthonormal 초기화는 random 초기화보다 좀 더 구분 가능한 $P$를 보여준다. 각 클래스 내에서 orthonormal 초기화는 노드가 그룹을 형성하도록 장려한다.
5 Discussion and Conclusion
본 논문에서는 brain network analysis를 위한 OCREAD를 갖춘 특화된 graph transformer를 제시한다. 두개의 대규모 brain network 데이터셋에 대한 광범위한 실험으로 BNT가 SOTA인 것을 확인했으며 brain network의 잠재적인 노드 기능 유사성을 모델링하기 위해 OCREAD를 설계하고 이론적, 경험적으로 그 효과를 입증한다. 마지막으로 ABIDE에 대한 재표준화된 데이터셋 분할은 커뮤니티의 새로운 방법에 대한 공정한 평가를 제공할 수 있다. 향후 작업을 위해 BNT는 explicit explanation modules을 통해 개선될 수 있으며 정신 장애에 대한 필수 신경 회로 발굴 및 청소년의 인지 발달 이해와 같은 추가 뇌 네트워크 분석을 위한 백본으로 사용될 수 있다.
개인적인 생각
- 본 논문은 brain network 관련 연구에서 베이스라인으로 사용되는 모델이라 자세히 리뷰를 하고 싶었는데, 일단 OCREAD라는 것이 나에게는 너무 어려워서 제대로 이해하지 못했다. 추후에 BNT에 대하여, 또 OCREAD에 대하여 자세히 공부할 일이 있으면 이론까지 공부를 하여 해당 본문을 수정할 의향이 있다.
- 기존 모델들이 왜 brain network에서 약한 모습을 보였는지 이해할 수 있었다. brain network의 고유한 특성에 대하여 이해할 수 있었다. 저자들의 뇌 기능에 관한 깊은 insight를 얻을 수 있어서 좋았다.
- brain network가 complete graph 라서 edge 정보가 불필요한 것을 이해하였으며 connection profile이 구조적 위치적 정보를 가지고 있는 것을 알게 되었다.
- 다시 원문을 보니 stratified sampling에 대하여 자세히 설명하지 않은 것 같다.
- 글을 보면 자연스럽지 못한 부분이 참 많은 것 같다. 이는 내가 이 논문을 완전히 이해하고 있지 못하다는 뜻이다. 여러모로 아쉬운 리뷰였지만, 이번 리뷰를 발판 삼아 더 나은 리뷰를 하는 블로거가 되어야겠다.