[논문리뷰] Interpretable fMRI Captioning via Contrastive Learning
MICCAI 2025 [Paper] [GitHub]
Vyacheslav Shen, Kassymzhomart Kunanbayev, Donggon Jang, Daeshik Kim 20 Sep 2025
1. Introduction
뇌의 계층적 이미지 처리는 CNN 개발에 영감을 주었다. CNN 레이어 전체에 걸쳐 특징과 돌출 맵을 시각화하면 초기 레이어에서 엣지를 감지하고 깊어질수록 클래스 특화된 특징을 감지하는 것은 시각 피질의 기능과 유사하다. 더욱이 CNN-learned representations는 원숭이와 사람의 neural activity와 강한 상관관계가 있다. 이런 유사성 덕분에 neural activity로 DNN feature를 역으로 예측하는 방식으로 DNNs는 visual representations를 디코딩하는데 많이 사용된다.
Huthet al.은 fMRI 데이터를 단어 임베딩에 매핑하여 몇 시간 분량의 서술된 이야기를 디코딩할 수 있음을 보여주었으며, 최근에는 LDM을 이용하여 fMRI 데이터로부터 고해상도 자극 이미지를 reconstruction 하는 연구도 있었다. 한편, Transformer 아키텍처와 GPT-2는 neural activity로부터 자연어 재구성을 크게 향상시켰다. 그러나 생성된 출력물의 품질과 의미론적 일관성을 위해 추가적인 개성과 대안이 필요하다. 기존에는 brain activity의 시각 자극에서 이미지를 재구성하는 방식으로 접근했으나, 최근에는 multimodal deep learning이 대안을 제공한다. 신경 반응을 바로 textual descriptions로 디코딩하는 것인데 이를 fMRI captioning이라고 한다. 이런 관점에서 multimodal retrieval은 brain activity로부터 무엇이 보였고 근본적으로 의미론적인 내용을 유연하게 디코딩할 수 있다. fMRI-based decoding의 발전에도 불구하고 효율적으로 brain activity와 의미 있는 textual descriptions을 align하는 것은 아직 여러 문제가 있는데, 연산 효율, 의미론적 일관성 그리고 retrieval capabilities이다. 본 논문에선 contrastive learning을 통해 이 문제를 해결한다.
본 논문의 contribution은 다음과 같다.
- 연산 효율이 좋은 two-stage training을 도입하여 fMRI 데이터와 VL model(BLIP-2)을 align한다.
- synthetic fMRI patterns을 이용하여 interpretability decoding analysis를 제안한다.
1.1 Related Work
CLIP (Contrastive Language-Image Pre-training)은 image 인코더와 text 인코더로 구성되며 multimodal model의 진보에 크게 기여했다. LDM의 reverse diffusion process에서 가이드를 하는 역할도 하고 VLMs에 LLMs과 visual data를 align 할 때도 사용한다.
이런 유능함에 힘입어 fMRI 신호로 CLIP의 image embedding을 예측하도록 하여 시각 자극을 재건하는 곳에 쓰인다. 그러나 breain decoding 연구에는 fMRI의 차원이 15,724로 충분히 고차원인데 conditional embedding 역시 257 × 768이나 257 × 1024 같은 고차원으로, 높은 연산량을 요구받는 어려움이 있다.
본 논문에서는 BLIP-2를 이용하여 visual embedding의 차원을 32 × 768로 compact하게 만든다. BLIP-2는 Q-Former(Querying Transformer)를 사용하여 이미지 인코더 기능을 LLM 임베딩 공간에 매핑한다. 압축 네트워크 역할을 하는 Q-Former는 대규모 frozen image features(257 × 1024)를 compact query tokens(32 × 768)으로 인코딩하여 뇌 디코딩에 적합한 텍스트 관련 및 의미론적으로 풍부한 이미지 표현을 보존한다.
2 Methodology
2.1 Dataset
Natural Scenes Dataset (NSD) 데이터셋을 사용한다. 이는 COCO dataset의 image를 각각 3초간 본 8명의 피험자의 7T fMRI 데이터셋이다. 기존 연구와 일관되도록 subj1의 데이터에서만 정량 분석을 한다. subj1은 모든 실험 시험을 완료하여 24,980개의 fMRI 시험(이미지당 최대 3회 반복)에 해당하는 8,859개의 훈련 이미지와 2,770개의 fMRI 시험이 포함된 982개의 테스트 이미지의 데이터 세트를 얻었다. 여러번 보여진 이미지에 대해서는 대응하는 fMRI trials에 대하여 평균을 취했다.
Ozcelik et al.을 따라 ridge regression을 사용한 GLM에서 억은 단일 실험 베타 가중치를 사용하여 fMRI를 처리했다. 시각 축을 따라 z-정규화했으며 NSDGeneral Regions-of-Interest (ROI) 마스크를 사용하여 15,764 복셀 벡터를 추출했다.
2.2 fMRI Captioning with BLIP-2
본 논문에서는 textual descriptions from fMRI activity를 생성하기 위해 pre-trained BLIP-2를 사용했다. 이는 compact language-aligned image representations (32 × 768)을 제공하기 때문이다.
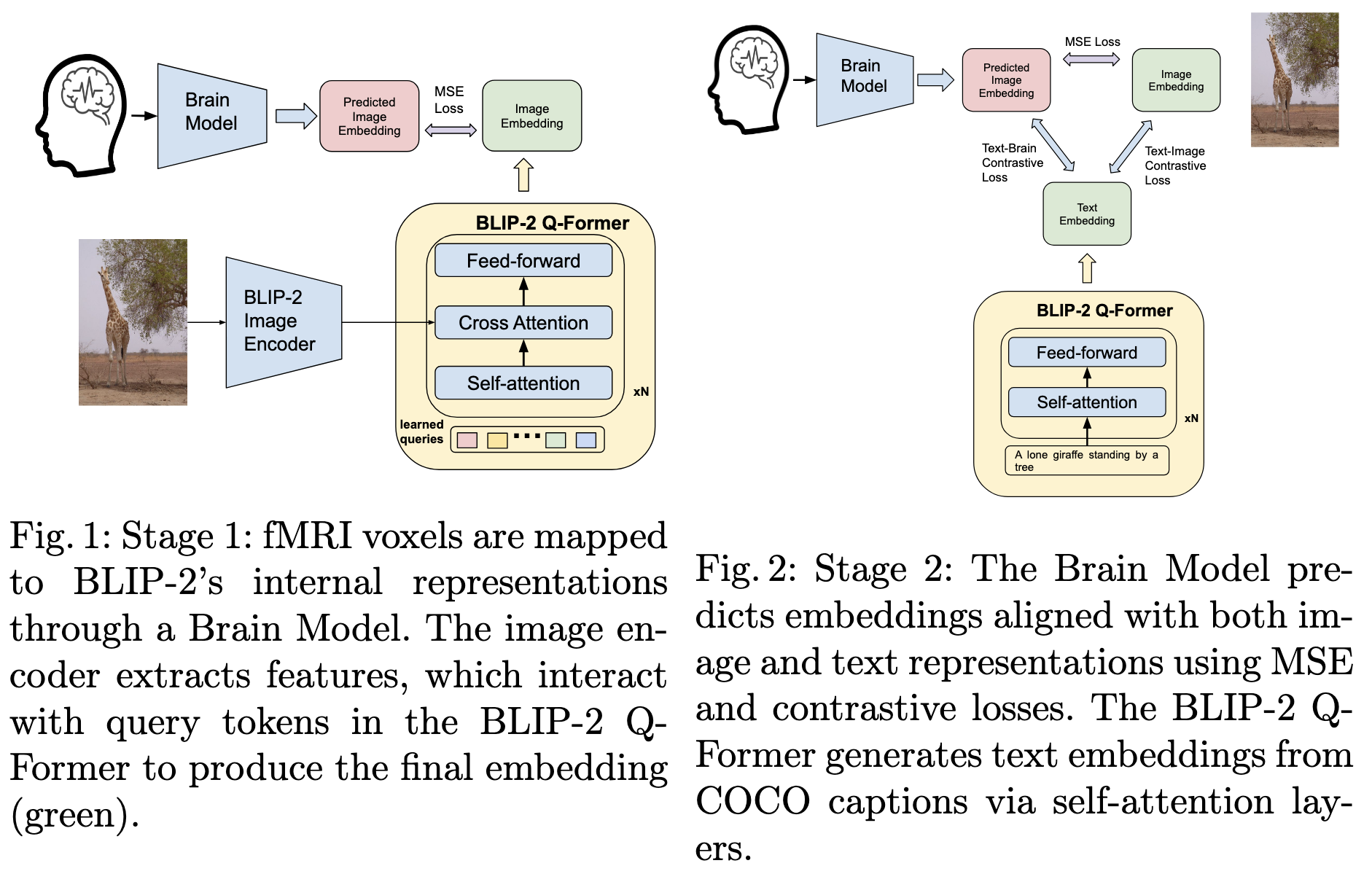
위 그림에서 볼 수 있듯이 feature extraction and Brain Model training으로 2 단계 프레임워크가 시작된다.
첫번째 단계에서는 stimulus image이 BLIP-2 이미지 인코더로 처리되고 BLIP-2 Q-Former안의 learned query vectors와 cross attention 하여 32 × 768의 최종 representation을 뽑는다. Brain Model은 ridge regression을 이용하여 fMRI activity(15,764 voxel)을 32 × 768의 최종 representation의 임베딩과 매핑한다.
두번째 단계에서는 retrieval을 위해 Brain Model의 출력과 text embeddings를 contrastive learning을 통해 align한다. GT caption은 BLIP-2 Q-Former’s self-attention 레이어를 통해 text embedding을 생성한다. image-text space와 Brain Model의 출력을 align하기 위해 linear projection layer를 도입한다. (fig 2 참고) 최종 loss는 다음과 같다.
\[\begin{equation} \mathcal L = \lambda_1\mathcal L MSE(b,i) + \lambda_2\mathcal L CLIP(b,t) + \lambda_3\mathcal L CLIP(i,t) \end{equation}\]역할은 다음과 같다.
- Mean Squared Error (MSE) loss: Brain Model’s predicted embeddings b 와 the GT image embeddings i의 alignment를 보존
- Brain-text contrastive loss: Brain Model’s outputs b 와 text embeddings t를 align해서 text retrieval 성능 향상
- Image-text contrastive loss: catastrophic forgetting 방지 및 t와 i의 일관성을 강화하며 robust image-text를 align
3 Results & Discussion
3.1 Retrieval
Multimodal Retrieval이란?
- 여러 종류의 데이터(뇌 신호, 이미지, 텍스트)를 서로 검색할 수 있는 능력
- 예시
입력 (Query) 검색 대상 (Retrieved) 의미 fMRI 뇌 신호 이미지 (B→I) “이 뇌 활동을 봤을 때 어떤 이미지를 본 거지?” 이미지 fMRI 뇌 신호 (I→B) “이 이미지를 봤을 때의 뇌 신호는 어느 것이지” fMRI 뇌 신호 텍스트 (B→T) “이 뇌 활동을 설명하는 문장은 무엇이지?” 텍스트 fMRI 뇌 신호 (T→B) “이 문장에 해당하는 뇌 신호는 어느 것이지?”
image and brain retrieval
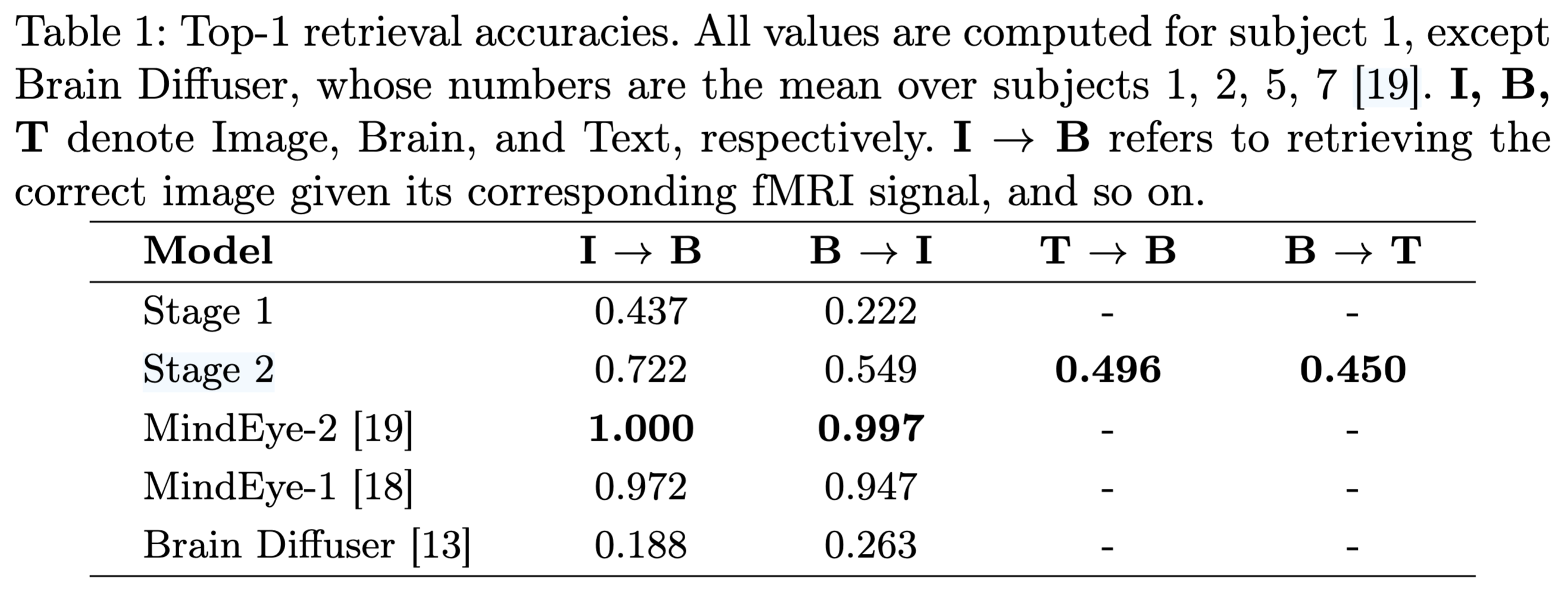
이미지를 BLIP-2 Q-Former representation으로 만들고 fMRI-derived representation과 image embedding의 cosine similarity를 계산한다. MindEye-2의 eval protocol을 따라 300 sample의 top-1 retrieval accuracy를 측정한다. 보고된 결과는 30번의 시도에 대한 평균 정확도를 반영한다.
text/brain retrieval
text-aligned image embedding을 stage 2의 Brain Model을 이용하여 예측한다. caption embedding을 BLIP-2 Q-Former를 이용하여 얻으며 올바른지 확인하기 위해 cosine similarity를 계산한다. 50번의 시도에 대한 평균 정확도를 보고 한다.
성능은 다음 표와 같으며 T → B와 B → T가 가능 한 모델임을 보여준다.
3.2 fMRI Captioning
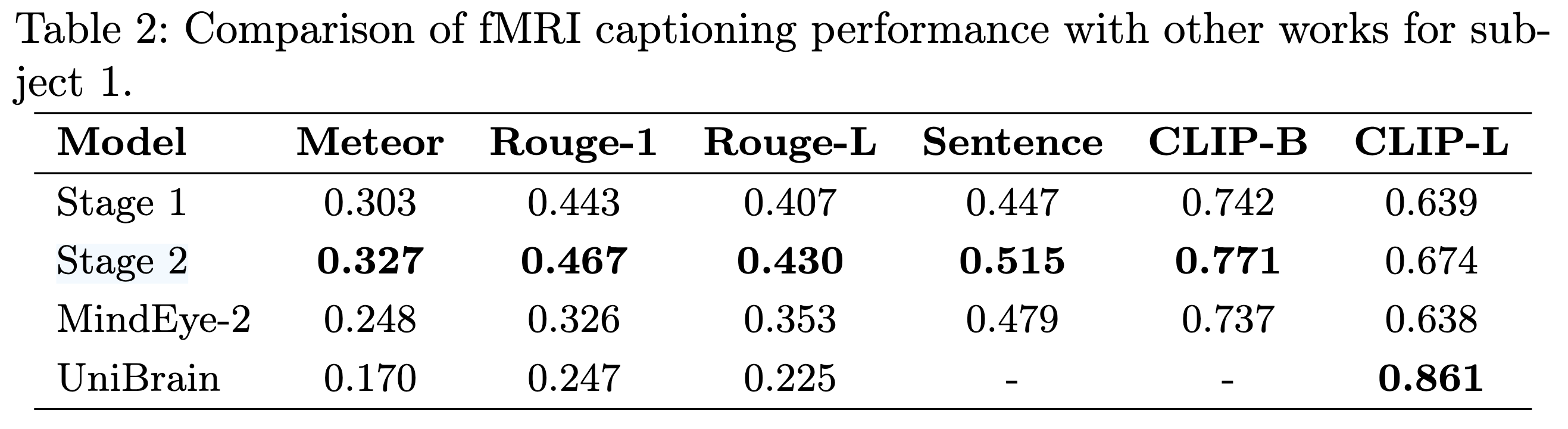
BLIP-2에 구현되어 있는 OPT-2.7B decoder-only language model를 이용하여 textual descriptions을 생성한다. 6개 중 5개에서 다른 모델들을 stage 1에서도 이미 넘어섰으며 stage 2는 압도적인 성능을 보인다.
아래의 Figure 4는 정성적인 성능을 보여준다. Stage 1보다 Stage 2에서 구체적인 caption이 나왔다. (beach 보다 wave, horses보다 zebra 등…)

3.3 Interpretability Analysis of ROI-Specific fMRI Signals
서로 다른 뇌 영역의 역할을 분석하기 위해 ROI-based interpretability analysis를 Brain Diffuser를 따라 한다. ROI의 voxel의 값을 1로 하고, 나머지를 0으로 만들어 synthetic fMRI 신호를 생성한다. Brain Model을 통해 처리 되고 정규화 후 11로 스케일되고 나서 caption 생성을 위해 language model을 통과한다. 아래 표는 그 결과이다.

이 결과는 인간의 계층적, 모듈적 특성을 반영하는 시각 처리의 신경과학적 연구 결과와 일치한다. 예를 하나만 들자면 V1은 basic black-and-white features를 highlight한다. floc-words 영역은 텍스트 및 기호와 관련된 caption을 생성한다. 이런 결과는 Brain Diffuser의 결과와 일관되게 같다.
4 Conclusion
본 논문에서는 연산 효율이 좋은 2 단계의 학습 프레임워크를 제안한다. contrastive learning을 도입하여 fMRI로 부터 정확한 captions을 생성하도록 하였으며, Vision-Language model representations과 brain activity를 align하여 multimnodal retrieval의 성능을 향상시켰다. ROI-optimal stimuli analysis는 decoding 과정에서 특정 뇌 영역의 contribuution을 식별하며 interpretability를 향상시켰다. 일반화 능력을 향상시키기 위해 cross-subject decoding에 초점을 두고, 적용 가능성을 향상시키기 위하여 multimodal generarion을 더 탐구하는 것을 future work로 두며 저자들은 글을 마무리 짓는다.
개인적인 생각
- 본 논문은 BLIP-2 Q-Former를 이용하여 연산 효율을 높이며 multimodal retrieval, fMRI captioning, Interpretability Analysis의 3가지 실험을 통해 우수성을 입증했다.
- 새로운 데이터셋을 통해 fMRI가 질환 연구에만 사용되는 것이 아닌 신경과학 분야에서 뇌를 이해하기 위해 사용되는 것을 확인하며 fMRI의 범용성을 알 수 있었다.
- b, i에서는 왜 MSE를 사용하고, 나머지는 왜 CLIP loss를 사용하는지 이해하지 못했는데 이유는 다음과 같다.
MSE: Brain Model의 출력 b가 Image Embedding i와 “최대한 똑같은 벡터값”이 되길 원함
CLIP: Brain Model의 출력 b가 Text Embedding t와 “의미적으로 가까운 공간”에 있길 원함 - 이 논문 역시 작년에 직접 설명을 들었었는데, 배경지식의 부족으로 그저 지나친 논문중에 하나였다. 이제 공부를 해서 어느정도 이해를 할 수 있어서 기쁘다. 저자분은 한국말을 잘하셨다.