[논문리뷰] Learning 3D Medical Image Models From Brain Functional Connectivity Network Supervision For Mental Disorder Diagnosis
MICCAI 2025 [Paper]
Xingcan Hu, Wei Wang, Li Xiao Thu, 6 Mar 2025
1. Introduction
blood-oxygen-level-dependent (BOLD)를 활용하여 뇌의 신경활동을 포착하는 fMRI는 대표적인 인간 뇌의 기능과 관련한 다양한 행동 및 인지적 특성에 관련한 비침습적 neuroimaging 기법이다. 최근엔 brain ROIs를 노드로, 각 노드의 기능적 연결을 엣지로 한 그래프인 Functional Connectivity Network(FCN)가 mental disorder를 진단하는데 많은 주목을 받고 있다. 지금까지는 FCN을 GNNs, CNNs, Graph Transformer로 학습을 해왔다. 그러나 아직 임상에는 널리 사용되지 않았는데 이는 fMRI 데이터 자체의 부족과 structure MRI(sMRI)에서 쉽게 얻을 수 있는 anatomical information과의 통합이 부족하다는 두가지 원인이 있다. anatomical structure가 근본적으로 뇌의 기능을 제한하기 때문에 mental disorder 진단에 더 나은 정밀도로 이끌 수 있다.
image-text pair의 contrastive learning의 성공에서 영감을 받아 의료쪽에서도 image-text, sMRI-fMRI 간의 멀티 모달 학습이 이루어지고 있다. 그러나 특정 모델을 사용해야 하며, 데이터가 부족하여 feature의 coarse representation로 인해 확장성이 떨어진다. 이와 관련하여 이 논문은 확장성에 초점을 두어 subject-level에서 sMRI와 fMRI를 contrastive pre-training한다. 3D T1w MRI-FCN 4619 쌍을 구성하고 Contrastive Image-Network Pre-training (CINP) framework를 구성하여 FCN Supervision을 통해 3D T1w MRI 영상의 representation을 학습한다.
Methods
2.1 Contrastive Image-Network Pre-training
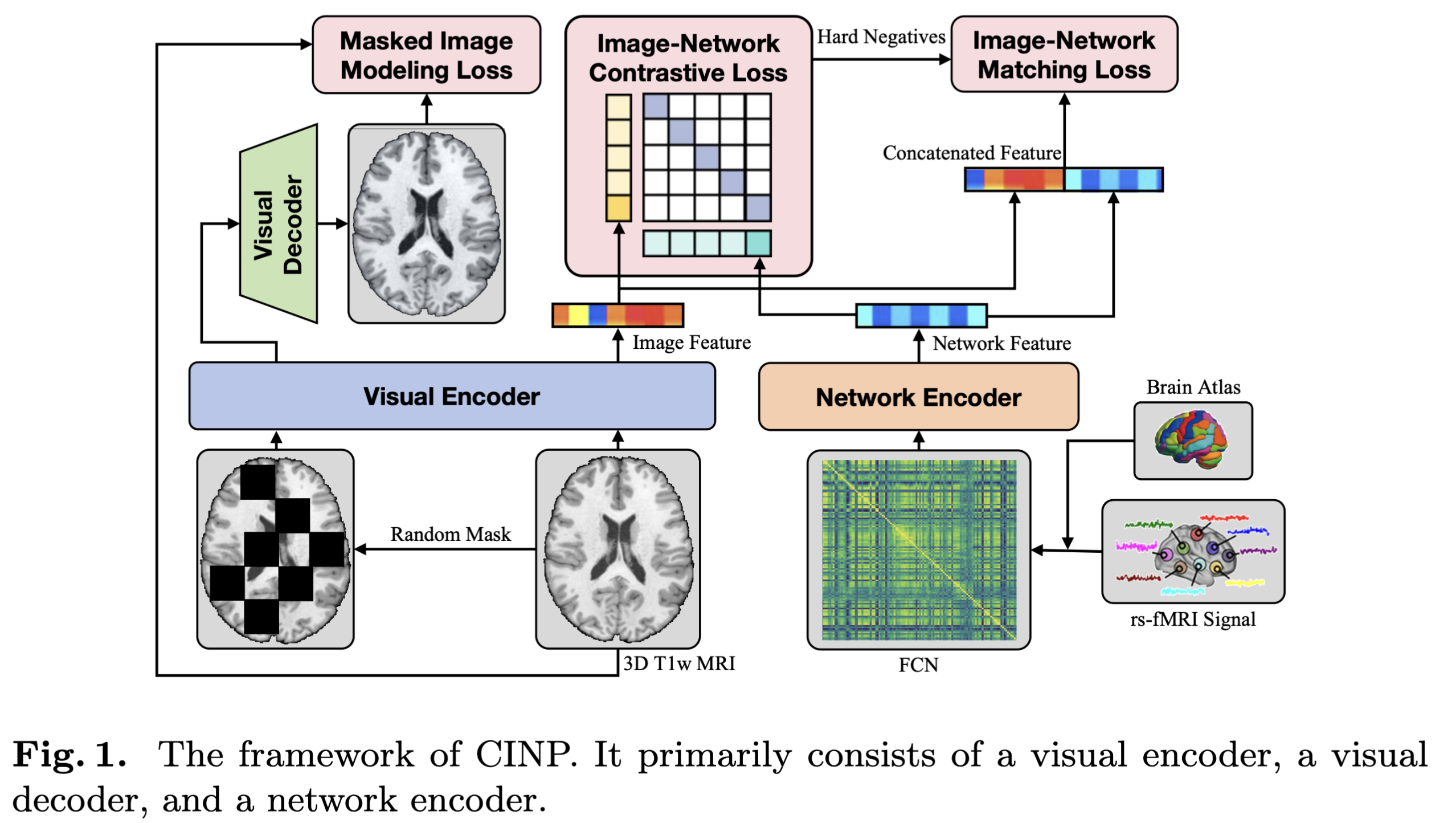
fig. 1에 명시되어 있듯 CINP는 visual encoder, visual decoder, network encoder로 구성되어 있다. visual encoder로는 Self-supervised pre-training of swin transformers for 3d medical image analysis 논문에서 weight로 초기화를 한다. 입력 3D T1w MRI 이미지 $I$는 전체 voxel의 30% 를 랜덤 마스크로 가려 masked MRI 이미지 $I^\ast$를 만든다. encoder를 통해 normalized image embedding $v_I$와 normalized masked image embedding $v^{\ast}_I$를 얻는다. (각 768D) visual decoder는 위의 언급한 논문의 구조를 따르며 $v^{\ast}_I$를 $\hat I$로 reconstruct 한다. Brain Network Transformer(BNT)를 network encoder로 사용하며 이는 FCN을 768 D의 normalized network embedding $w_N$로 인코딩한다.
Image-Network Contrastive Learning(CINP)는 CLIP의 성공에 영감을 받아 image-network 간 contrastive learning을 통해 FCN Supervision으로 활용하여 3D T1w MRI의 representation을 강화하는 학습 방법이다. 자세히 설명하면 similarity score $s(I, N)=v_I^T w_N $가 있을때 같은 subject이면 더 높은 score를 다른 subject이면 더 낮은 score를 받도록 학습한다. 배치에서 각 image와 network는 softmax-normalized image-to-network와 network-to-image similarity는 다음과 같이 계산된다.
\[\begin{equation} p_k^{in}(I)=\frac{exp(s(I,N_k)/\tau)}{\sum^K_{k=1}exp(s(I,N_k)/\tau)} \quad and \quad p_k^{ni}(N)=\frac{exp(s(N,I_k)/\tau)}{\sum^K_{k=1}exp(s(N,I_k)/\tau)} \end{equation}\]여기서 $\tau$는 학습가능한 파라미터이고 K는 배치 사이즈이다. $y^{in}$과 $y^{ni}$를 모든 image와 network의 GT(positive는 1, negative는 0)라고 할때, cross entropy $H(\cdot , \cdot)$를 통헤 image-network contrastive(INC) loss를 다음과 같이 구성한다.
\[\begin{equation} \mathcal{L}_{INC}=\frac{1}{2}\mathbb{E}_{(I,N)~D}[H(y^{ni}(I),p^{ni}(I))+H(y^{in}(N),p^{in}(N))] \end{equation}\]Masked image modeling (MIM)은 MRI 이미지의 robust representation을 구성하는 것을 목표로 한다. $L_1$를 이용하여 학습한다.
\[\begin{equation} \mathcal{L}_{MIM}=\mathbb{E}_{(I,\hat I)~D}||I- \hat I ||_1 \end{equation}\]Image-network matching (INM)은 image-network pair가 같은 subject에서 왔는지 파악하는 이진 분류 문제이다. $v_I$와 $w_N$을 concatenation 하여 fully-connected layer를 통과하여 이진 분류 확률인 $q$를 얻는다. \(\begin{equation} \mathcal{L}_{INM}=\mathbb{E}_{(I,N)~D}[H(z_{INM},q(I,N))] \end{equation}\)
이때 $z_{INM}$은 GT label로 2D one-hot vector이다. 위의 세 Lossf를 합하여 CINP loss는 다음과 같이 구성된다.
\[\begin{equation} \mathcal{L} = \mathcal{L}_{INC}+\alpha\mathcal{L}_{MIM}+\beta\mathcal{L}_{INM} \end{equation}\]2.2 Network prompting
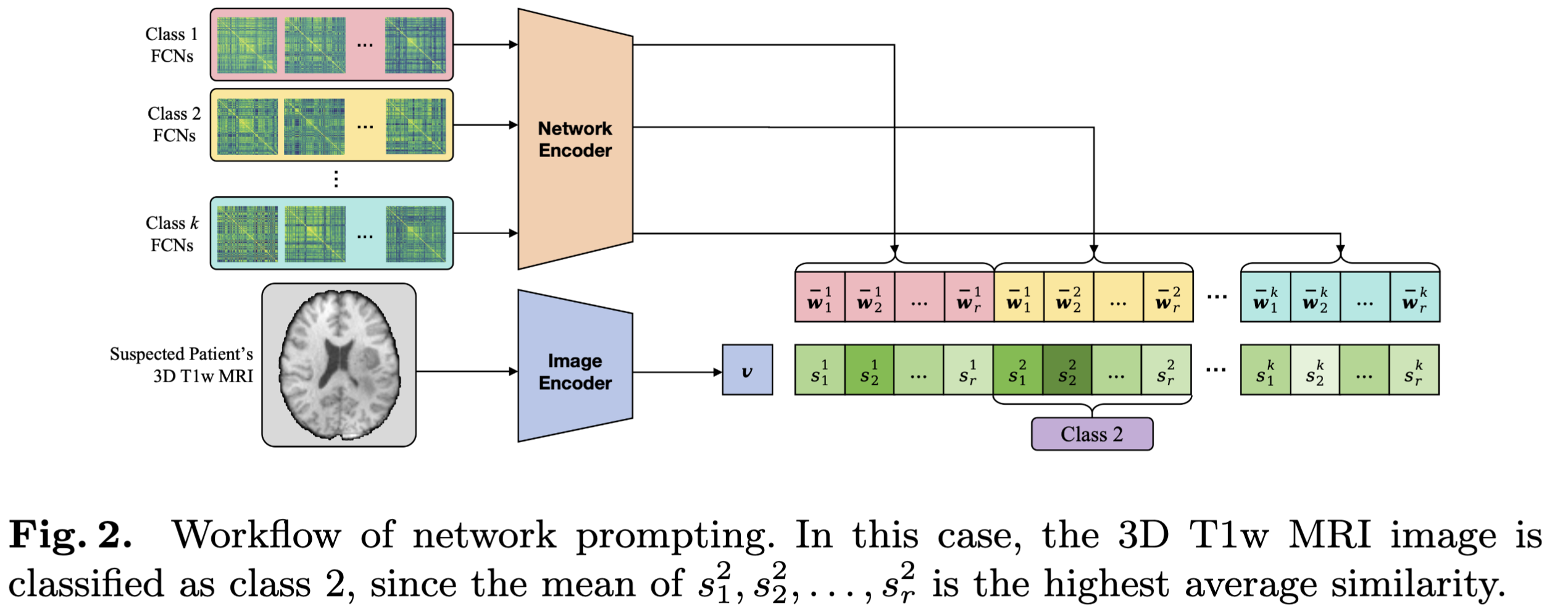
기존의 연구들은 linear probe나 fine-tunning을 사용하여 downstream task에 사용한다. 이는 많은 양의 annotated data를 요구하는데, fMRI는 정기적으로 수집되지 않는 문제가 있다. 저자들은 이 문제를 해결하기 위해 서로 다른 subject에서 FCNs이 significant한 group-level 차이를 보이는 것에서 영감을 받아 network prompting을 사용한다(fig. 2). 이들은 pre-trained CINP가 3D T1w MRI 이미지 embedding과 FCN embedding이 공동의 semantic space에서 학습됐기에 이들의 similarity를 측정할 수 있다는 가정을 한다.
k subject class에서 network embedding set $\mathcal{U}={\mathcal{C_1},\mathcal{C_2},…\mathcal{C_k}}$을 얻는다. 이때 $\mathcal{U}$ 의 각 원소는 n개의 FCNs를 포함한다. $\mathcal{C_l}= { w^l_1, w^l_2, … w^l_n }$ for $l=1,2,…k$. 또한 각 class 별로 FCNs을 r개의 같은 크기의 분리된 하위 집합으로 나누면 다음과 같이 표기할 수 있다. \(\mathcal{C}_l = \bigcup_{i=1}^{r} \mathcal{C}_l^i, \quad \mathcal{C}_l^i \cap \mathcal{C}_l^j = \emptyset \ (i \ne j), \quad |\mathcal{C}_l^i| = \frac{|\mathcal{C}_l|}{r}.\)
같은 subset 안의 network embedding은 평균이 내어져서 r group-level reference network embeddings를 구성한다: $\mathcal{\bar U}={{\bar w^i_1, \bar w^i_2,…\bar w^i_r,}|l=1,2,…,k},$ where $\bar w^i_l=\frac{1}{|\mathcal{C^i_l}} \sum_{w \in \mathcal{c^i_l}}w$ for $i=1,2,..,r$, 이는 subject-level biases를 지우는 것을 도와준다. 그리고 난 후에 3D T1w MRI의 image embedding인 $v$를 reference network embedding과 유사도인 $\mathcal{S}={{s^l_1,s^l_2,…,s^l_r}|l=1,2,…,k}$ where $s^l_i=v^T\bar w^l_i$ for $i=1,2,…r$를 구한다. 각 class의 FCNs와의 평균 similarity $\mathcal{\bar S}={\bar s^1,\bar s^2,…,\bar s^r}$, where $\bar s^l = \frac{1}{r} \sum_{i=1}^r s^l_i$ for $l=1,2,…k,$를 구하고 가장 높은 avg. similarity를 이용하여 환자에게 class를 할당한다.
3. Experiments
3.1 Experimental Settings
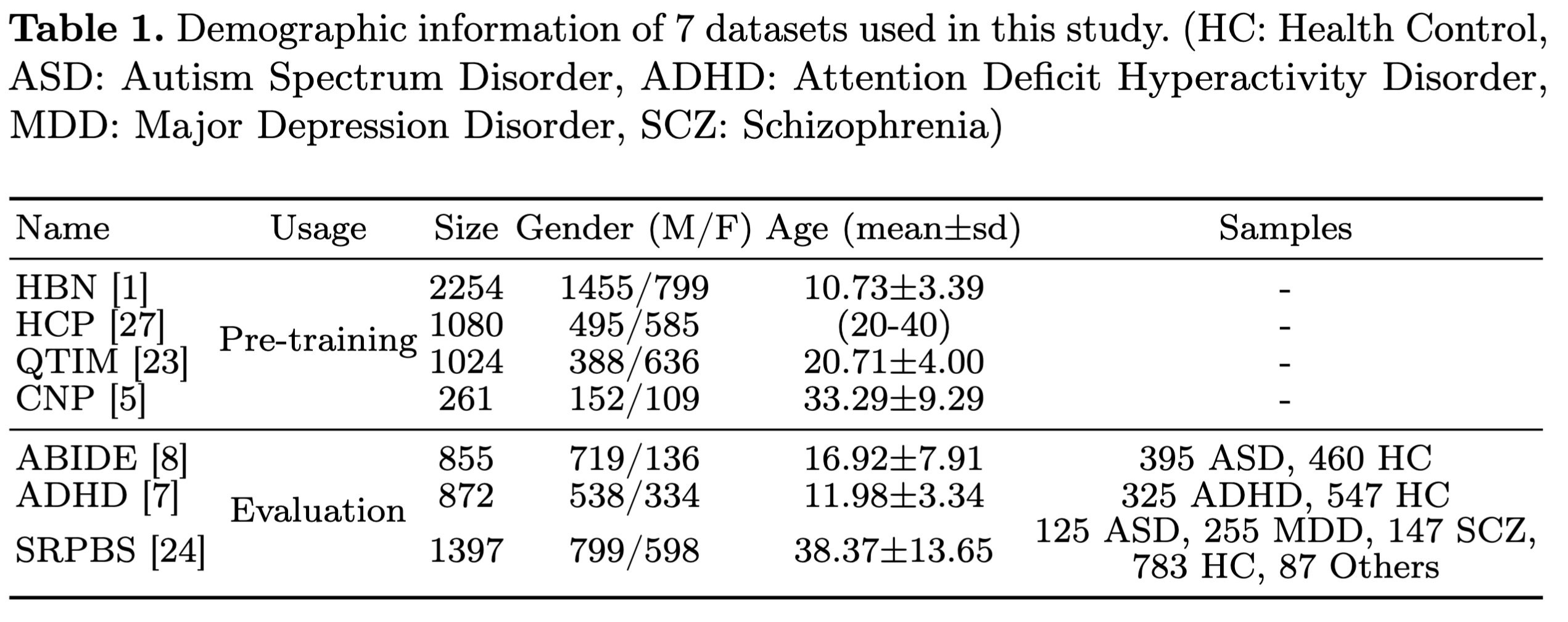
저자들은 공공 데이터를 이용하여 3D T1w MRI and resting-state fMRI (rs-fMRI) 데이터셋을 구성했다. 4개의 데이터셋을 pre-training에 사용한다(HBM, HCP, QTIM, CNP). evaluation에는 ABIDE, ADHD, SRPBS의 세개의 데이터셋을 이용한다. fMRIPrep preprocessing pipeline을 이용하여 전처리 했으며 모든 mri의 복셀 크기는 $2\times2\times2 mm^3$로 preprocessing 되었다. rs-fMRI로부터 FCNs를 뽑기 위해 116개의 ROIs를 가진 AAL atals를 피어슨 상관계수로 사용했다. 자세한 데이터에 관한 설명은 아래 표를 참고하면 된다.
Implementation Details은 다음과 같다.
- lr: 1e-5 (weight decay of 1e−5)
- cosine annealing schedule (1e−6)
- batch size(K): 256
- epoch: 8 $\times$ NVIDIA A800 ($\approx$ 100 hours)
- $\alpha = \beta = 1$
- augmentation: Gaussian noise addition, flipping, intensity scaling and shifting
- resize: $96 \times 96 \times 96$
- linear probe protocol: SVM / train:val:test=7:2:1
evaluation 시 임상에서 부족한 FCNs을 반영하기 위해 FCNS의 10%만을 사용한다.
3.2 Quantitative Results
아래 표에서 볼 수 있듯이 ADHD와 SRPBS에서 가장 좋은 ACC를 얻었다. 이는 sMRI-based model과 비교했을때 ABIDE, ADHD, and SRPBS 데이터셋에서 1.46%, 1.26%, 1.21% 차이가 난다. 이는 sMRI와 FCNs을 contrastive learning 함으로 상호 보완적인 정보를 완전히 포착할 수 있어서 mental disorder diagnosis에 도움을 준다는 것을 확인할 수 있다.
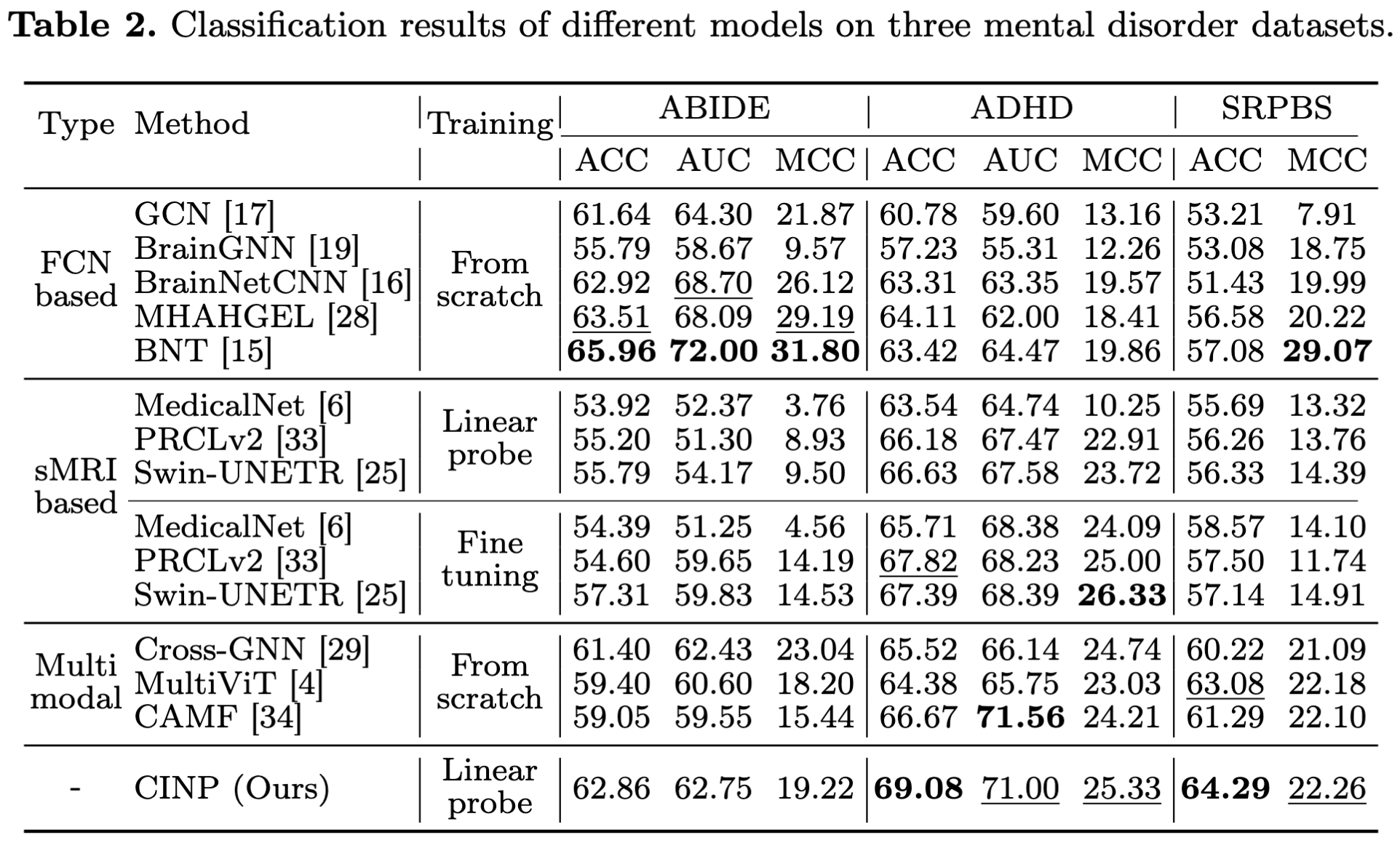
그러나 ABIDE에서는 SOTA 급 성능을 내지 못했는데 이는 ADHD 진단에 sMRI의 정보가 더 필요하다는 것을 의미할지도 모른다고 저자들은 말한다.
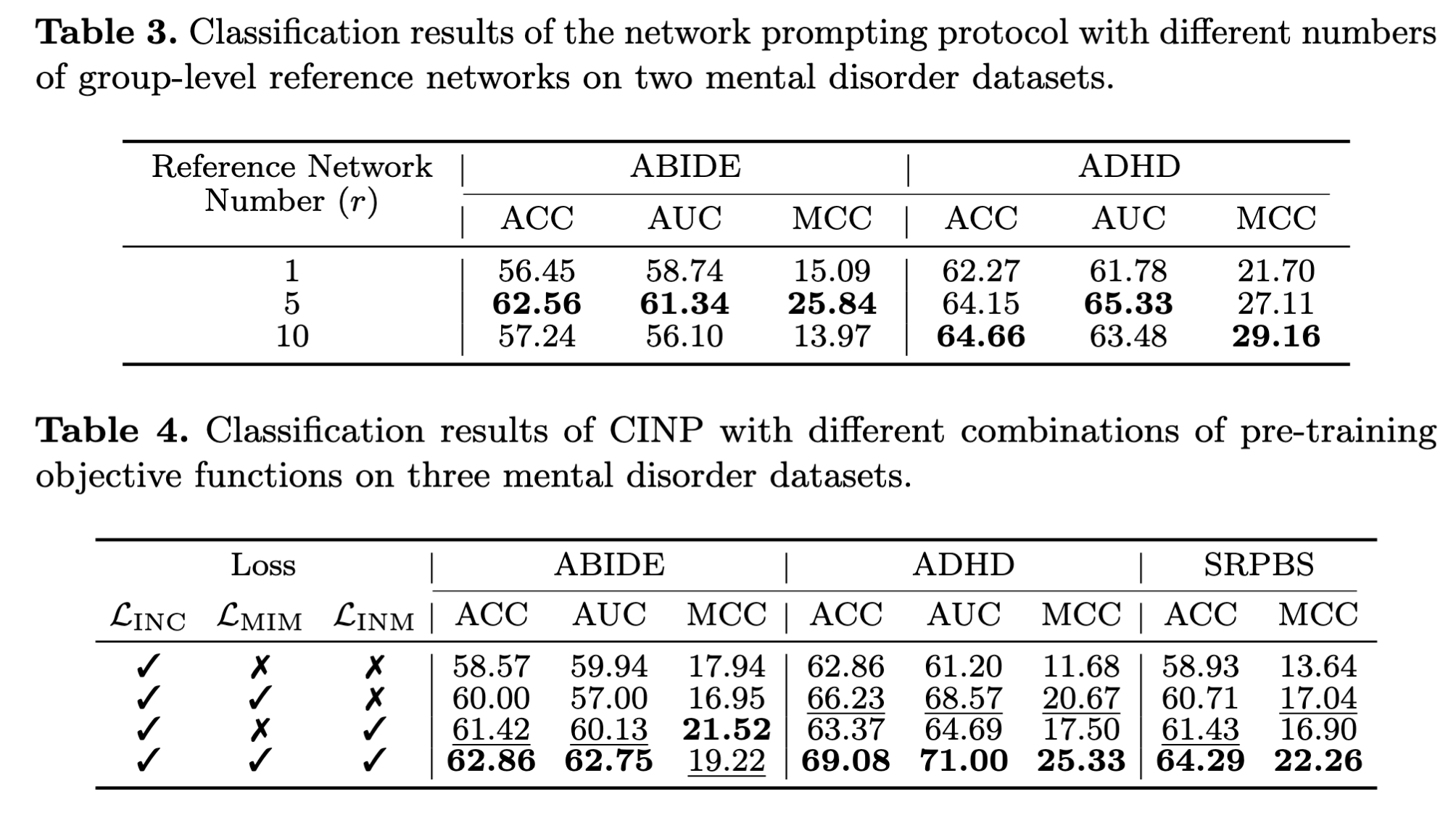
table 3은 network prompting에 대한 ablation study 결과이다.
3.3 Ablation Study
table 4는 Loss에 대한 abltation study 결과이다.
4. Conclusion
본 논문에서 저자들은 3D T1w MRI와 FCN을 contrastive learning하는 framework인 CINP을 소개한다. mental disorder diagnosis의 성능을 향상시키기 위해 pre-training 하는 동안 3개의 loss가 3D T1w MRI image의 representation 품질을 FCN supervision으로 향상시켰다. 또한 network prompting을 도입함으로 적은 양의 FCN으로 환자가 sMRI만 촬영하여 예측에 사용하는 것이 가능하도록 한다. 3개의 데이터셋에서 CINP의 효과를 입증하였으며 sMRI를 임상 진단에 통합하는 것에 대한 가능성을 보여준다.
개인적인 생각
(1) fMRI는 촬영 시간이 길고 1회 촬영이 비싸서 환자들이 정기적으로 검사를 받기 어려운 modality이다. 그런 현실적인 상황을 검증시에 반영하였으며 network prompting이라는 기법으로 꽤 잘해결했다. 그럼에도 불구하고 ABIDE dataset에서 BNT에 밀린 것은 다소 아쉽다. 또한 github에 코드가 공개되어 있지 않은 것도 아쉽다.
(2) 이 논문을 통해 fMRI에 관심이 생겼었다. BOLD란 무엇인지 FCN이 뭐고 어떻게 계산되고 활용되고 있는지 공부할 수 있어서 좋았다. 앞으로도 fMRI를 사용한 논문을 자주 찾아볼 것 같은데 큰 도움이 되었다.
(3) 여담으로 작년 MICCAI에서 저자의 포스터 발표를 들었는데 저자분께서 매우 친절하게 잘 설명해주셨던 기억이 난다.