[논문리뷰] Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
CVPR 2023 [Paper] [GitHub]
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, Nicolas Ballas 13 Apr 2023
1. Introduction
CV 분야에서는 invariance-based method와 generative method라는 두가지 SSL 기법이 있다. invariance-based pretraining method는 같은 이미지의 서로 다른 view에서 비슷한 임베딩을 얻으며 최적화한다. 이때 서로 다른 view는 hand-crafted augmentations를 통해 주로 만든다. 이 pretraining 기법은 high semantic level의 representations을 얻을 수 있지만, 특정 task나 다른 데이터 분포에서 강한 편향을 주입하기도 한다. 다양한 수준의 추상화가 필요한 task에 대해 이런 편향을 일반화하는 것은 아직 불분명한 경우가 많다. 예를 들어 image classification과 instance segmentation은 같은 invariance를 요구하지 않는다. 추가적으로 image-specific augmentation을 audio 같은 다른 모달에 일반화하는 것은 간단하지 않다.
Cognitive learning theories는 생물학적 시스템에서 representations learning 이면에 있는 구동 메커니즘은 감각 입력 반응을 예측하기 위한 내부 모델의 adaptation이라고 제안한다. 이 아이디어는 self-supervised generative methods의 핵심이다. 이는 입력의 일부를 제거하거나 오염시키고 해당 부분을 예측하는 방식이다. Masked pretraining task는 view-invariance method 보다 사전 지식(hand-crafted transformers을 의미하는 것 같음.)이 덜 필요하고 다른 모달에 일반화 성능이 좋다. 그러나 invariance-based method보다 낮은 semantic 수준을 보이며ㅡ off-the-shelf evaluation에서 성능이 낮다. 결과적으로 end-to-end fine-tunning 같은 복잡한 adaptation 메커니즘을 활용해야 이 방법의 완전한 이점을 누릴 수 있다.
본 논문에서는, I-JEPA라는 추가 사전 지식 없이 self-supervised representations의 semantic 수준을 높이는 method를 도입한다. I-JEPA의 핵심 아이디어는 abstract representation space(추상 표현 공간)에서 누락된 정보를 예측하는 것이다. 예를 들어 같은 이미지의 단일 context block를 주고, 여러 target block의 representation을 예측하는 것이다.
pixel/token space에서 예측하는 generative methods에 비해 I-JEPA는 불필요한 pixel-level 디테일이 잠재적으로 지워진 target의 abstract를 예측함으로 model이 더 의미있는 특징을 학습하도록 이끌어낸다.
I-JEPA를 더 semantic representations을 생산하도록 선택된 또 다른 핵심 디자인은 multi-block masking strategy이다. 특히 이미지에서 충분히 큰 target blocks를 예측하도록 하는 것의 중요성을 입증한다.
저자들은 방대한 양의 실험을 통해 다음을 입증한다.
- strong off-the-shelf representation을 hand-crafted view augmentation없이 학습한다.
- I-JEPA는 view-invatiant pretraining approaches와 비등한 semantic task 결과를 보였고, low-level visions tasks에서는 더 나은 결과를 보였다.
- I-JEPA는 scalable하고 효율적인다.
2. Background
SSL은 system이 입력간의 관계를 포착하도록 하는 representation learning 기법이다. 이 목표는 incompatible inputs 끼리는 높은 에너지를, compatible inputs끼리는 낮은 에너지를 할당하는 Energy-Based Models(EBMs)의 프레임워크를 이용하여 쉽게 설명 가능하다. 현존하는 많은 SSL 방법들이 이 프레임워크로 설명가능하다. 다음 그림을 보면 이해가 쉽다.
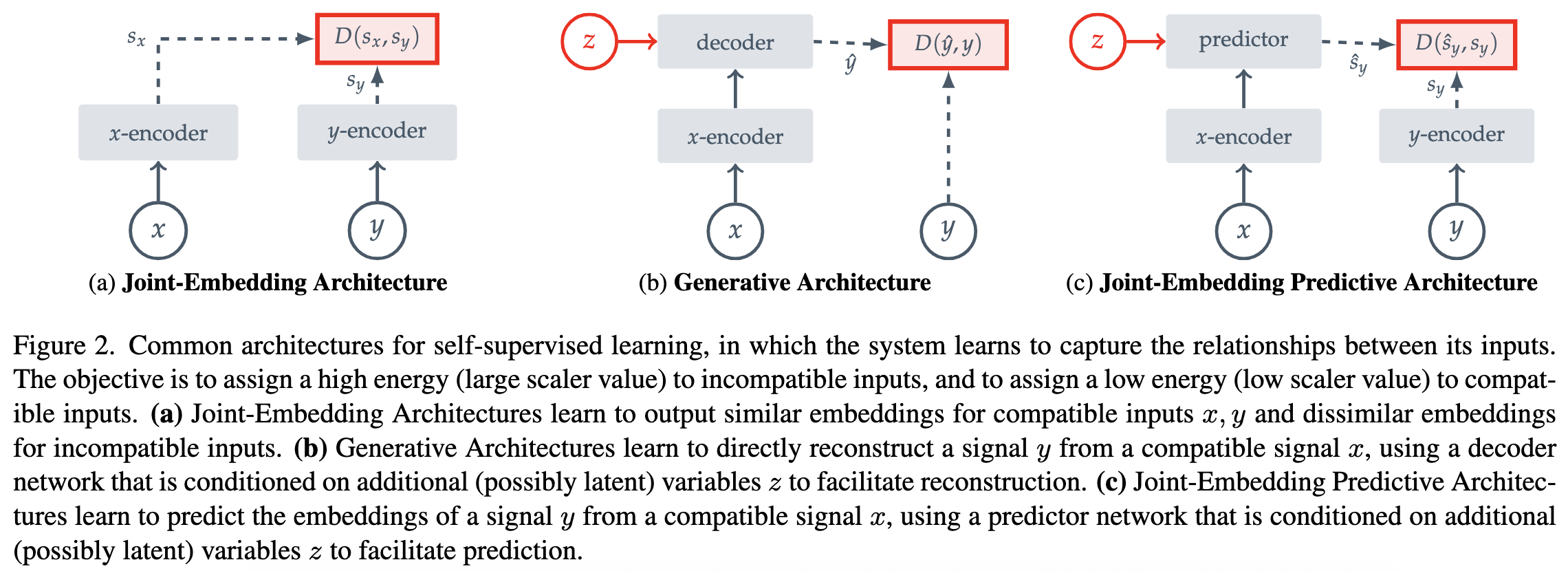
Joint-Embedding Architectures
Invariance-based pretraining methods는 compatible inputs인 $x,y$ 간에 비슷한 embedding을 산출하고,incompatible inputs에는 다른 embedding을 산출하느 Joint-Embedding Architectures을 사용하는 EBMs로 설명가능하다(Figure 2a.). image-based pretraining의 관점에서 compatible inputs인 $x,y$는 주로 같은 입력 이미지에 랜덤하게 hand-crafted augmentation을 적용하여 만든다. JEAs의 주된 과제는 energy landscapes가 평평해 지는 representation collapse이다(입력에 관계없이 완전히 같은 출력을 내보냄.). 지난 몇년간 representation collapse을 방지하기 위한 다양한 방법이 연구되었다. contrastive loss를 사용하거나 non-contrastive loss를 사용하여 embedding간 정보 중복을 최소화 하거나 평균 임베딩의 엔트로피를 극대화하는 clustering-based 등의 방법이 있다. 또 서로 다른 인코더를 사용해서 collapse를 방지하는 방법도 있다.
Generative Architectures
Reconstruction-based method 역시 Generative Architectures를 사용하는 EBMs 프레임워크로 설명할 수 있다(Figure 2b.). Generative Architectures는 compatible signal $x$에서 바로 $y$를 reconstruction한다. 이때 디코더는 이를 촉진하기 위해서 $z$를 추가적으로 조건으로 받는다. image-based pretraining의 관점에서 가장 흔한 compatible inputs $x,y$를 만드는 방법은 masking이다. $z$는 mask와 position token이다. 이는 어느 이미지 패치를 디코더가 reconstruction할지 명시해준다. $y$보다 $z$의 정보 용량이 적은한 representation collapse는 문제가 되지 않는다.
Joint-Embedding Predictive Architectures
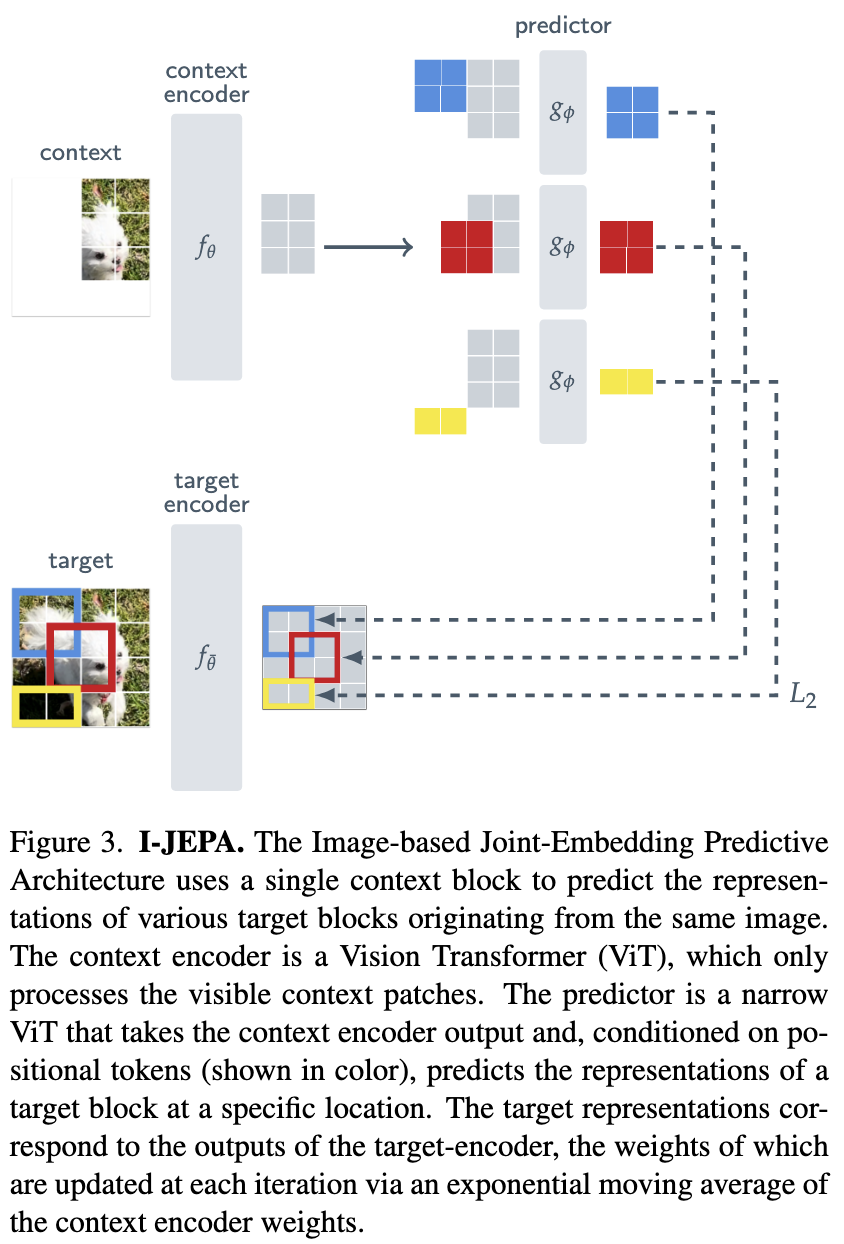
Figure 2c.에서 볼 수 있듯이 Joint-Embedding Predictive Architectures는 Generative Architectures와 비슷하다. 이와 가장 큰 차이는 loss 계산이 input space가 아닌 embedding space에서 일어나는 것이다. JEPAs는 예측을 용이하기 위한 변수 $z$를 조건으로 받아 compatible signal $x$로 부터 signal $y$의 임베딩을 예측 네트워크를 통해 예측하도록 학습한다. 자세한 그림은 Figure 3.을 참조하면된다.
JEA와 다르게 JEPAs는 representation invatiant를 hand-crafted augmentation을 이용하여 representation invatiant를 찾지 않고 대신 추가 정보 $z$를 조건으로 할 때 서로를 예측하는 representation을 찾는다. 그러나 JEA와 마찬가지로 representation collapse는 JEPAs에서도 문제가 되는데, 이를 방지하기 위해 $x$와 $y$ 사이에 비대칭 아키텍처를 사용한다.
3. Method
Figure 3.을 다시 한번 보자.
I-JEPA의 전반적인 목적은 같은 이미지에서 context block이 주어졌을때 다양한 target block의 representation을 예측하는 것이다. context-encoder와 target-encoder 모두 ViT를 사용하였으며 decoder구조는 MAE에서 따왔다. 둘의 차이는 I-JEPA는 non-generative method이며 prediction이 representation space에서 일어나는 것이다.
Targets
주어진 입력 이미지 $y$를 겹치지 않는 N개의 패치를 만든다. target-encoder $f_{\bar \theta}$에 이걸 넣어서 대응하는 patch-level representation $s_y=\lbrace s_{y1},…, s_{yN} \rbrace $을 만든다. loss를 위한 targets를 얻기 위해 $s_y$에서 M개의 랜덤한 sample block을 뽑는다. i번째 블록에 대응하는 마스크를 $B_i$로 표시하고 $s_y(i) = \lbrace s_{yj} \rbrace _{j \in B_i}$로 표시한다. 저자들은 실험에서 M=4로 셋하고 0.75:1의 종횡비와 0.15~0.2의 스케일로 block을 샘플링했다.
Context
I-JEPA의 목표는 single context block으로 부터 target block의 representation을 예측하는 것이다. 이를 위해 이미지의 0.85~1의 스케일로 $x$를 샘플링하고 $B_x$를 이용해 context blocks을 할당한다. 이후 target block과 겹치는 부분을 없애준다. 아래 그림이 target blocks와 context block을 이해하는데 도움을 준다.

Prediction
context encoder의 출력 $s_x$가 주어졌을 때 우리는 $M$ 개의 target block의 representation $s_y(1), \ldots, s_y(M)$ 을 예측하기를 바란다. 이를 위해, 대상 마스크 $B_i$ 에 해당하는 주어진 target block $s_y(i)$ 에 대해 예측기 $g_\phi(\cdot, \cdot)$ 는 context encoder의 출력 $s_x$와 예측하려는 각 패치에 대한 마스크 토큰 $\lbrace m_j \rbrace_{j \in B_i}$ 를 입력으로 취하고 패치 수준 예측 \(\hat{s}_{y}(i) = \lbrace \hat{s}_{yj} \rbrace_{j \in B_i} = g_\phi(s_x, \lbrace m_j \rbrace_{j \in B_i})\) 을 출력한다. mask token은 positional embedding이 추가된 shared learnable vector이다.
Loss
loss는 predicted patch-level representations $\hat{s}_y(i)$과 the target patch-level representation $s_y(i)$간의 평균 $L_2$ distance이다. predictor, $\phi$와 context encoder, $\theta$는 gradient based optimization을 target encoder $\bar \theta$는 EMA 방식으로 학습한다.
4. Related Work
본문에서 다양한 SSL 기법에 대한 설명을 하고 있으나 이 글에서는 다루지 않겠다.
5. Image Classification
ImageNet-1K
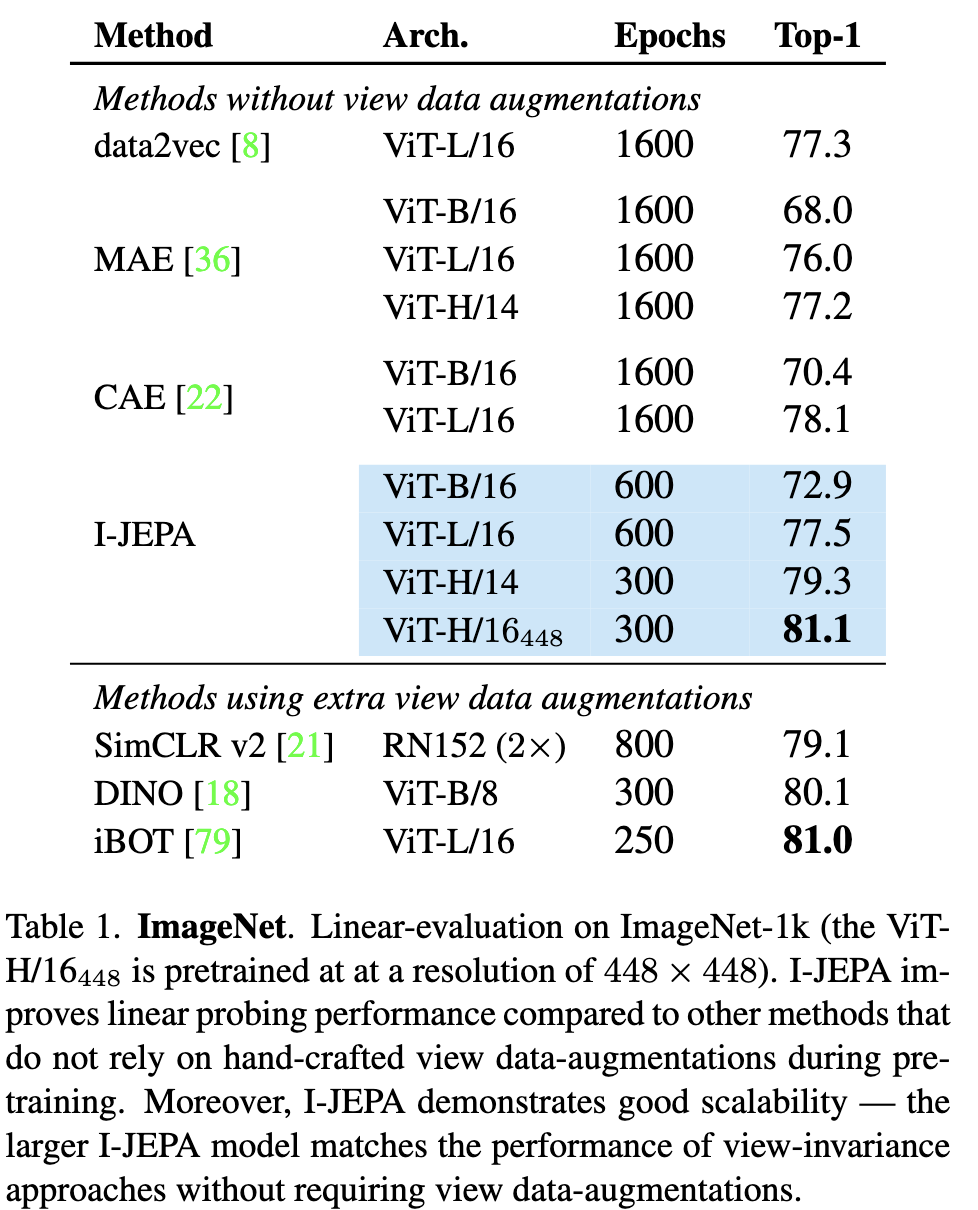
hand-crafted augmentation을 사용하지 않는 다른 유명한 방법인 MAE, CAE 그리고 data2vec과 비교했을때 I-JEPA는 더 적은 연산으로 linear probing 성능을 향상시켰다.
Low-Shot ImageNet-1K

IN1k의 1%(각 클래스 별로 12~13 장)으로 학습한 결과이다. 적은 에폭으로도 비슷한 구조의 MAE보다 나은 성능을 보였다. 이미지 해상도가 높아져도 JEAs보다 더 나은 성능을 보인다.
Transfer learning
기존 모델들 보다 더 좋은 성능을 보였으며 view-invariance-based와의 간격도 줄었다.

6. Local Prediction Tasks
- 에서 I-JEPA의 강력함을 엿볼 수 있었는데 이 섹션에서는 I-JEPArk local image feature를 학습하고 low-level이고 dense prediction task에서 view-invariance based method보다 더 나은 결과를 보임을 입증한다.
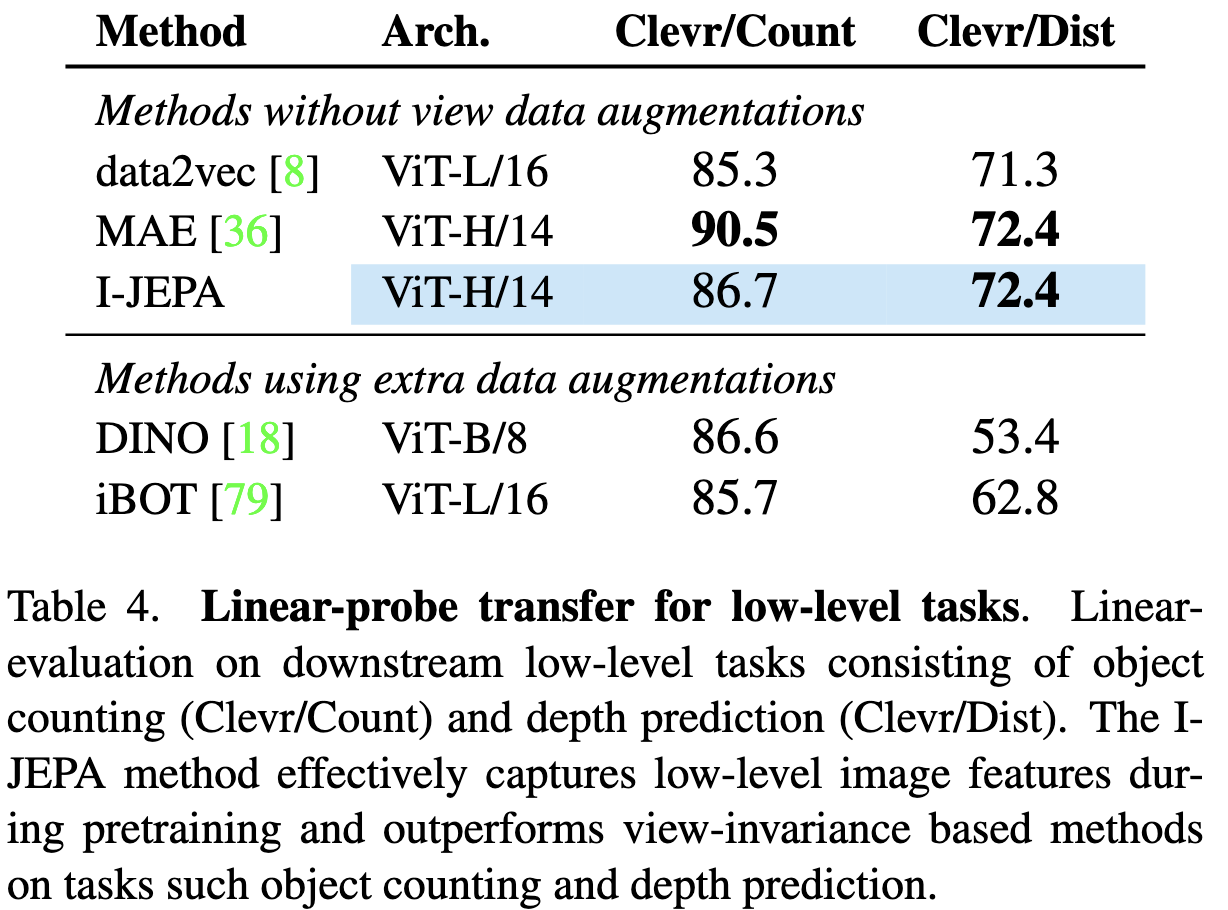
7. Scalability
Model Efficiency
I-JEPA는 기존 방법들보다 더 높은 확장성을 제공한다. MAE 같은 reconstructionbased methods는 픽셀을 target으로 삼는 반면, I-JEPA는 representation space에서 계산을 하기 때문에 약간의 오버헤드가 있다. 그러나 5배 더 빠른 수렴을 보여준다. 또한 I-JEPA로 ViT-H/14를 학습하는 것 보다 ViT-S/16으로 iBOT을 학습하는 것이 더 적은 연산을 필요로 한다.
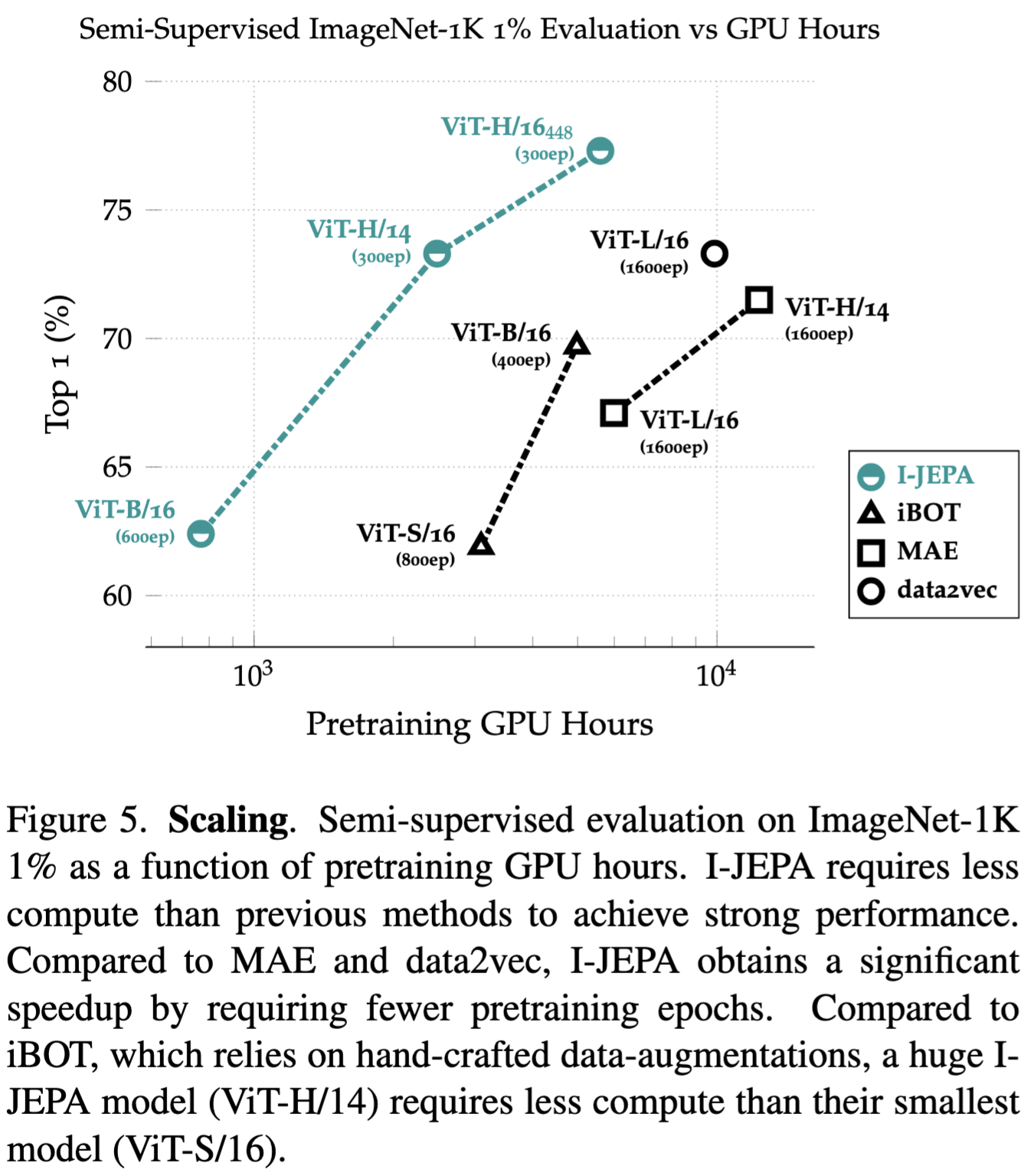
Scaling data size
I-JEPA는 더 큰 데이터셋에서 pretraining할 때 효과적임을 아래 표를 통해 확인할 수 있다.
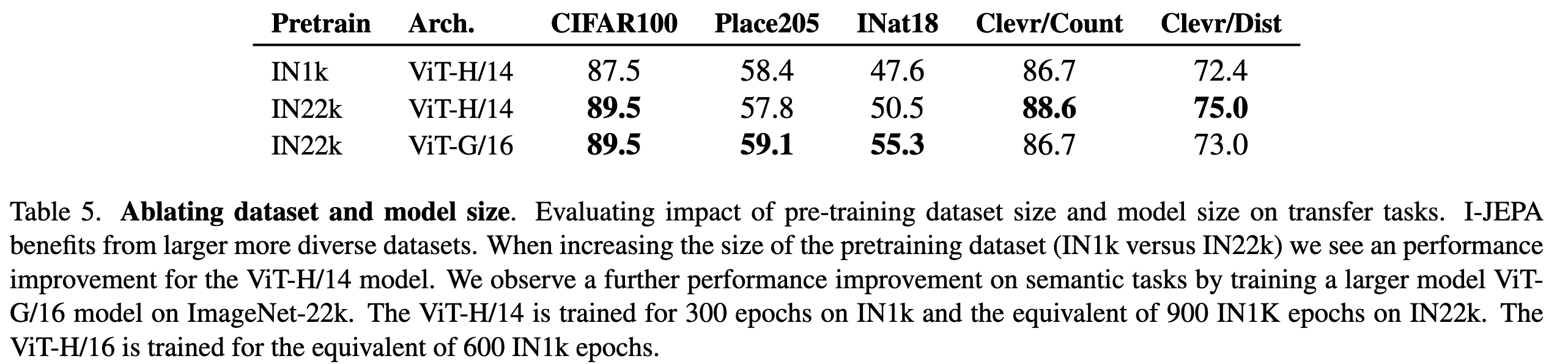
Scaling model size
위 표는 I-JEPA가 더 큰 모델에서 pretraining을 할때 더 효과적임을 입증한다. 그러나 ViT-G/16은 입력 팿치가 더 커서 local prediction task 성능이 안좋다.
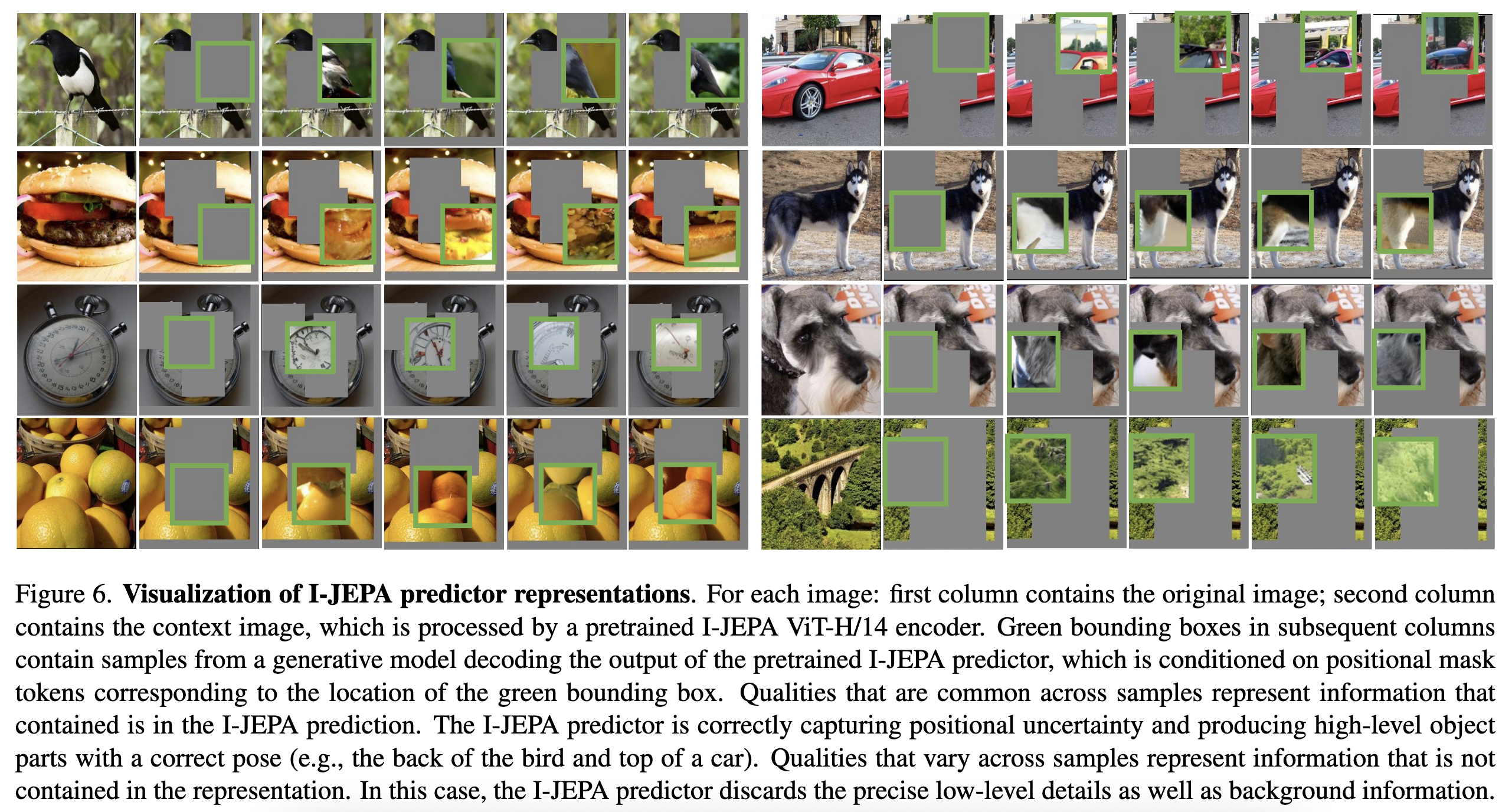
8. Predictor Visualizations
I-JEPA로 학습한 모델을 RCDM framework로 생성을 시킨 결과이다. I-JEPA의 predictor는 고수준 object의 부분을 정확한 Pose로 잘잡아낸다.
9. Ablations
Predicting in representation space
pixel space vs representation space에서 loss를 계산할 때의 성능 차이를 ImageNet-1K 1% linear probe로 비교한 실험이다.
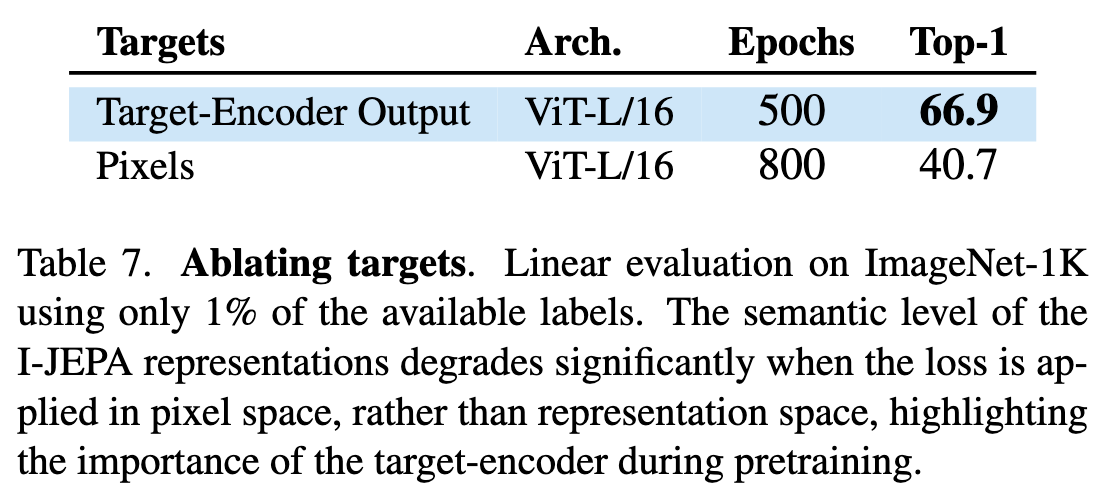
pixel space에서 예측하게 되면 모델이 픽셀 수준의 세부 정보(텍스처, 조명, 노이즈 등)까지 다 맞춰야 해서 representation이 low-level detail에 오염된다. 그러나 representation space에서 예측하게 되면 target encoder가 추상적인 예측 타겟을 만들 수 있으므로 의미없는 픽셀 수준 디테일이 제거된 상태로 학습된다.
Masking strategy
다양한 마스킹 전략을 ablation한 결과이다. multi-block masking이 I-JEPA가 semantic representation을 학습하는 데에 도움이 되는 가이드를 하는 것을 알아냈다.

10. Conclusion
본 논문에서 저자들은 I-JEPA를 소개한다. I-JEPA는 hand-crafted augmentation에 의존하지 않으며 semantic image representation을 학습하는 간단하고 효율적인 방법이다. I-JEPA는 다른 pixel-level의 방법보다 빠르게 수렴하며 높은 수준의 semantic representation을 학습한다. view-invariance based method와 달리 I-JEPA는 and-crafted augmentation에 의존하지 않고 JEA를 사용하여 general representation을 학습할 수 있는 경로를 강조한다.
개인적인 생각
- 오랜만에 CV 이론 논문을 리뷰해서 introduction에 힘을 줘버려서 Experiments 부분을 제대로 리뷰하지 못한 것 같아서 아쉬웠다.
- 얀 르쿤이 심열을 기울인 방법으로 디테일이 크게 돋보인 논문이었다.
- 아직 익숙하지 않은 개념이라, 따로 드는 생각은 없는 것 같다. 코드를 한번 뜯어봐야겠다.