[논문리뷰] A Simple Framework for Contrastive Learning of Visual Representations
ICML 2020 [Paper] [Github]
Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton
1 Jul 2020
Introduction
Supervision 없이 visual representations를 효율적으로 학습하는 것은 오랫동안 문제였다. 이를 위해 Generative와 Discriminative 두가지 접근이 있었다. Generative 접근법은 입력 공간에서 픽셀을 생성하는 방식을 학습하는 접근법인데 계산 비용이 비싸고 representation learning을 위해 불필요한 방식이다. Discriminative 접근법은 unlabeled dataset을 이용하여 supervised learning과 비슷한 방식으로 representation을 배운다. contrastive learnin을 기반으로 한 Discriminative 접근법이 SOTA 방식이다. 지금껏 contrastive learning은 memory bank같은 특별한 구조를 사용하여 연구가 되어왔으나 본 논문에서는 위 사실에 기반하여 간단하고 특별한 archtecture가 필요없지만 성능이 좋기까지 한 simple contrastive learing framework를 제안한다. 본 논문에서 집중해서 봐야하는 부분은 다음과 같다.
- 여러 augmentation을 조합하여 효과적인 representation을 산출
- representation과 contrastive loss 사이에 learnable non-linear transformation을 도입
- 적절한 temperature parameter와 함께 사용하는 contrastive cross entropy loss
- 큰 batch size가 주는 효율, contrastive learning은 더 깊고 넓은 네트워크에서 오래 학습할수록 좋음.
Method
SimCLR은 최근 연구에 영향을 받아 같은 데이터 샘플에서 서로 다르게 augment된 view 끼리 latent space에서 최대한 일치하게 representation을 학습한다.
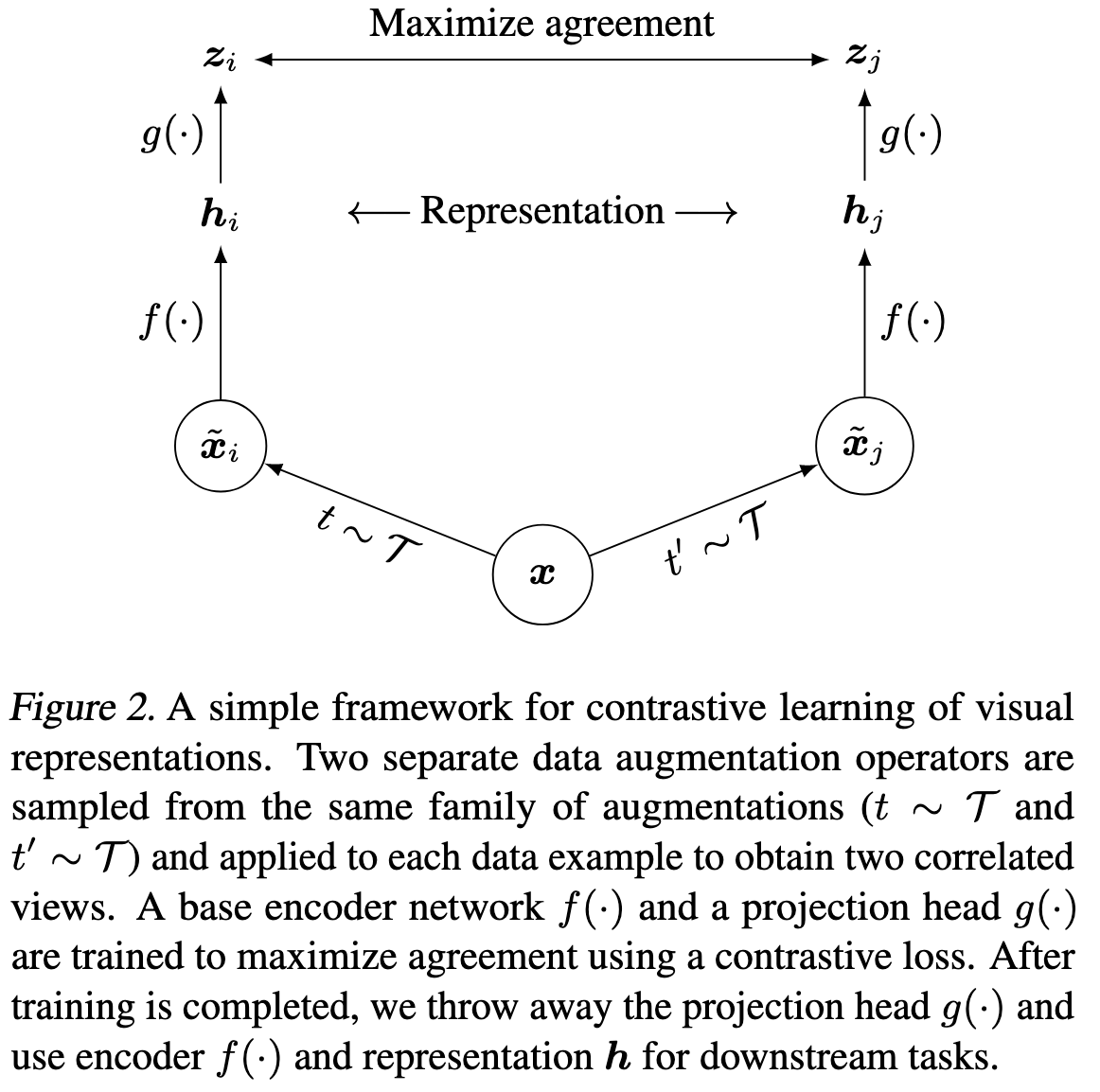
augmentation은 random {cropping, color distortion, Gaussian blur}를 사용한다. 잠시 후 소개하겠지만 random crop과 color distortion 조합이 가장 좋았다.
모델은 정말 간단하다. 구현의 간소화를 위해 encoder $f(·)$는 ResNet을 활용했다. 우리는 방금 한 말을 $h_i=f(\tilde{x}_i)=ResNet(\tilde{x}_i)$로 간단히 표현할 수 있는데, 이때 $h_i \in \mathbb{R}^d$는 avg pooling layer 이후의 출력이다. fig2를 보면 Projection head $g(·)$를 볼 수 있는데 이는 그냥 간단한 MLP다 이를 통해 우리는 $z_i$를 얻을 수 있고 $z_i=g(f(\tilde{x}_i))=W^{(2)}\sigma(W^{(1)}h_i)$로 표현할 수 있다. 여기서 sigma는 ReLU를 의미한다.
그 다음은 Loss를 설명할 차례인데, NT-Xent(the normalized temperature-scaled cross entropy)los를 도입한다. (CPC라는 연구에서 소개된 InfoNCE와 비슷한 형태를 가지고 있다.) 수식은 다음과 같다.
\[\begin{equation} l_{i,j}=-\log\frac{exp(sim(z_i,z_j)/\tau)}{\sum^{2N}_{k=1}\mathcal{1}_{[k \neq i]}exp(sim(z_i,z_k)/\tau)} \end{equation}\]글쓴이의 추가 설명!
이 수식 뭔가 복잡해보일지 모르겠다. 필자 역시 그랬다. 이 수식을 이해하기 위해서는 the normalized temperature-scaled cross entropy의 이름을 잘 이해해야 한다.
normalize: $l_2$ normalize 해줘서 붙은 이름이다. $\text{sim}$은 similarity를 의미한다. $\text{sim}(u, v) = \frac{u \cdot v}{|u| |v|}$ 으로 표현 가능하며 두 벡터가 가리키는 방향이 얼마나 유사한가를 의미한다.(-1~1) 이때 $l_2$로 normalized된 $u$, $v$는 cosine similarity다. 참고로 $l_2$로 만들면 vector의 크기도 항상 1로 같게 되는데 [1]에 의하면 학습 안정성과 linearly separable하다는 장점이 있다.
temperature-scaled: $\tau$ 로 scaling을 하면 hard negative mining에 강점이 생긴다. 이는 본 논문에서 소개할 예정이다.
cross entropy: 이 부분이 가장 이해하기 어려웠다. 흐린 눈으로 위의 수식을 바라보자 익숙한 녀석들이 보일거다. 분모와 분자에 exp가 있다. 맞다. softmax다. 이는 확률로 anchor($z_i$)가 이 positive($z_j$)를 다른 모든 샘플들 중에서 구분해낼 수 있느냐를 의미한다.
여기까지 이해가 됐어도 다음과 같은 질문이 생길 수 있다. 내가 아는 cross entropy는 CE = -∑ y_true[i] × log(y_pred[i])인데 왜 -log(softmax)만 남았을까? 왜냐하면 positive인지 negative인지 2N-1 class classification이며 label을 One-hot encoding 했기 때문이다. 아래 부분을 참고하길 바란다.
CE = -∑ y_true[i] × log(y_pred[i])
= -(1 × log(y_pred[정답 인덱스]) + 0 × log(y_pred[오답1]) + 0 × …)
= -log(y_pred[정답 인덱스])이 짧은 글이 독자님들께 아주 조금이라도 도움이 되길 바란다.
pseudo code로 나타낸 알고리즘은 다음과 같다.

SimCLR이 나타나기 전까지는 memory bank라는 기술을 통해 학습을 했다. 그러나 SimCLR은 구현의 단순함을 위해 batch size를 256에서 8192로 대폭 증가시켰다. SGD/momentum 방식은 큰 batch엣에서 불안정하기 때문에 LARS optimizer를 사용한다.
분산 학습 환경에서는 global batch normalization을 도입했다. 이를 하지 않으면은 모델이 accuracy 성능만 높이고 representation의 품질은 향상시키 않는다고 언급한다. MoCo같이 shuffling을 하거나 Layer normalization을 하는 방법도 있다.
학습 후에 검증을 위해 ImageNet 1k과 CIFAR10 dataset에 대하여 다양한 검증을 했다. default setting으로는 random crop&resize, color distortion, Gaussian blur로 augmentation을 했으며,ResNet-50 에 128차원으로 projection하는 2 layer MLP을 모델로 사용한다. loss는 NT-Xent, optimizer는 LARS learning rate는 4.8 (= 0.3 × BatchSize/256) 그리고 weight decay of 10−6으로 줬다. batch size는 4096 for 100 epochs이다. 또 첫 10 epochs에 linear warmup과 learning rate를 cosine decay로 decay했다.
Data Augmentation for Contrastive Representation Learning
이 논문이 주는 또 다른 시사점은 Self-supervised learning에서 Data augmentation의 역할이다. 아래와 같이 다양한 augmentation 전략이 있다.

이들 중 최적의 조합을 찾기 위해 ablation study를 했다. 다음 그림에 의하면 Crop+Color distortion 전략이 ImageNet 1k linear probing에서 가장 높은 정확도를 기록했다. 우선 하나의 augmentation만 하면 좋은 representation을 얻지 못했으나 두개의 augmentation을 조합하면 식별은 좀 어렵지만, representation의 품질이 드라마틱하게 향상된다.
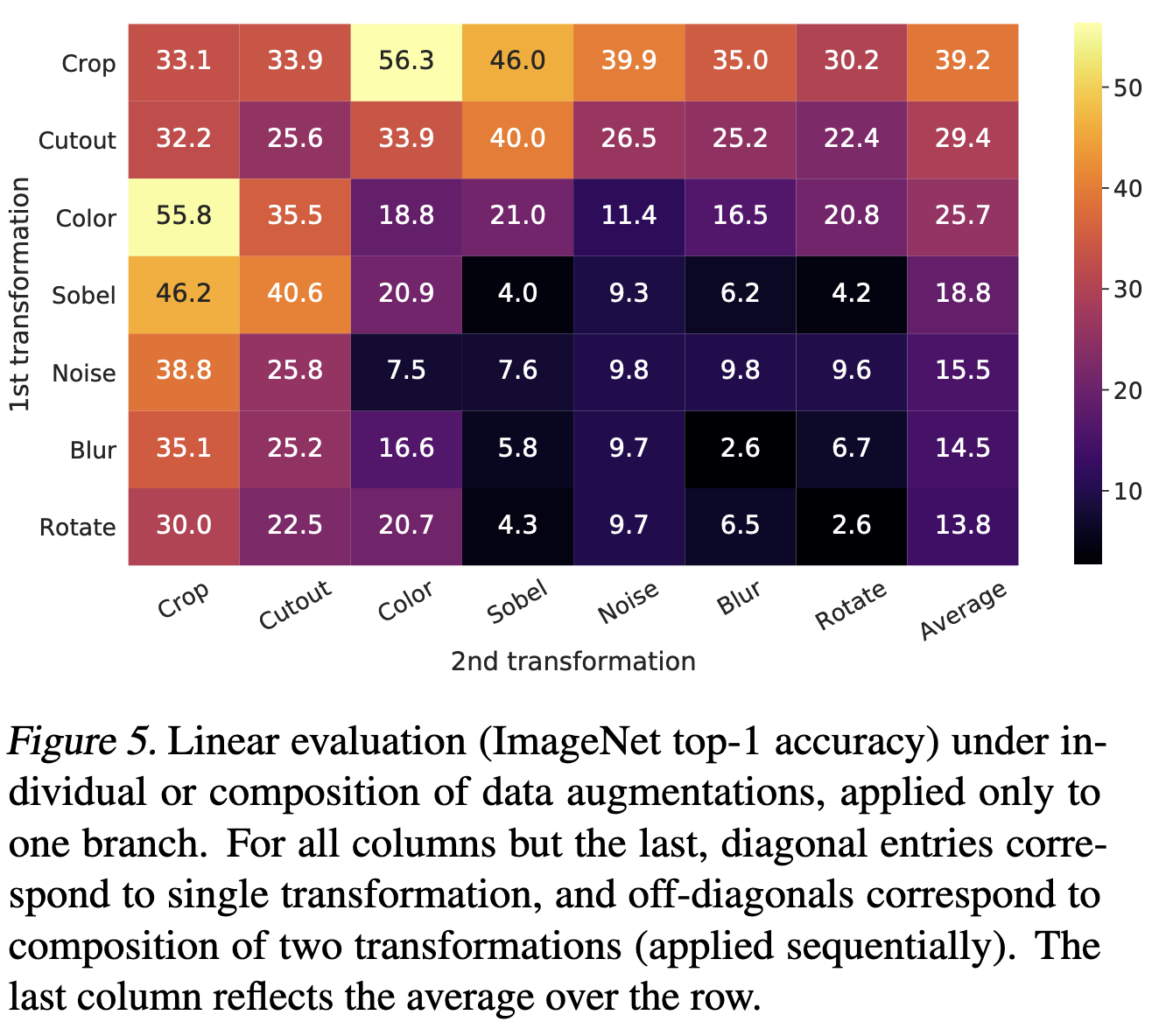
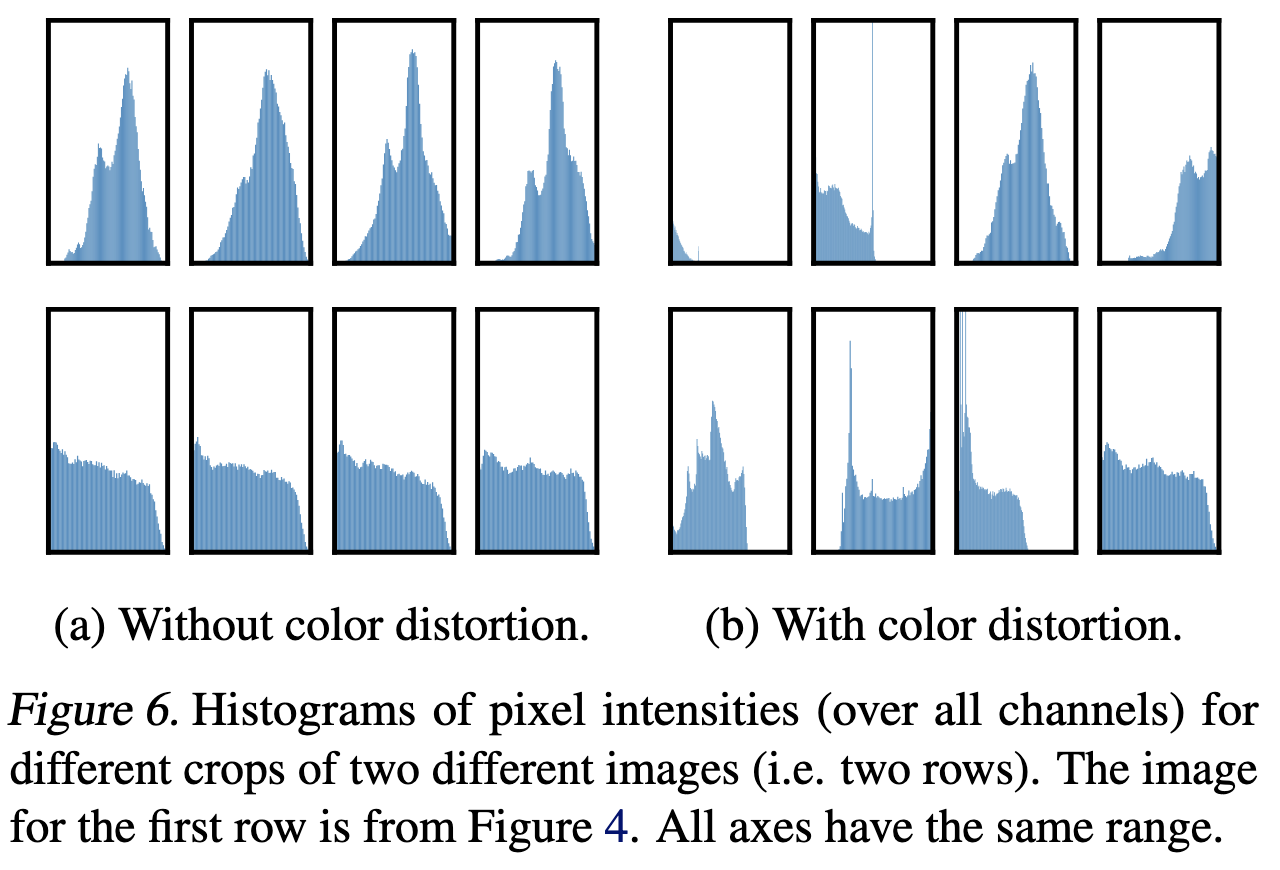
저자들이 분석한 이유로는 crop만 하면 대부분의 patch가 비슷한 색상 분포를 가지게 되는데 그것만으로도 충분히 네트워크가 식별 할 수 있었기 때문에 crop별로 color distortion을 다르게 적용하는 것이 더 높은 일반화 성능을 가질 수 있다고 설명한다.
Architectures for Encoder and Head
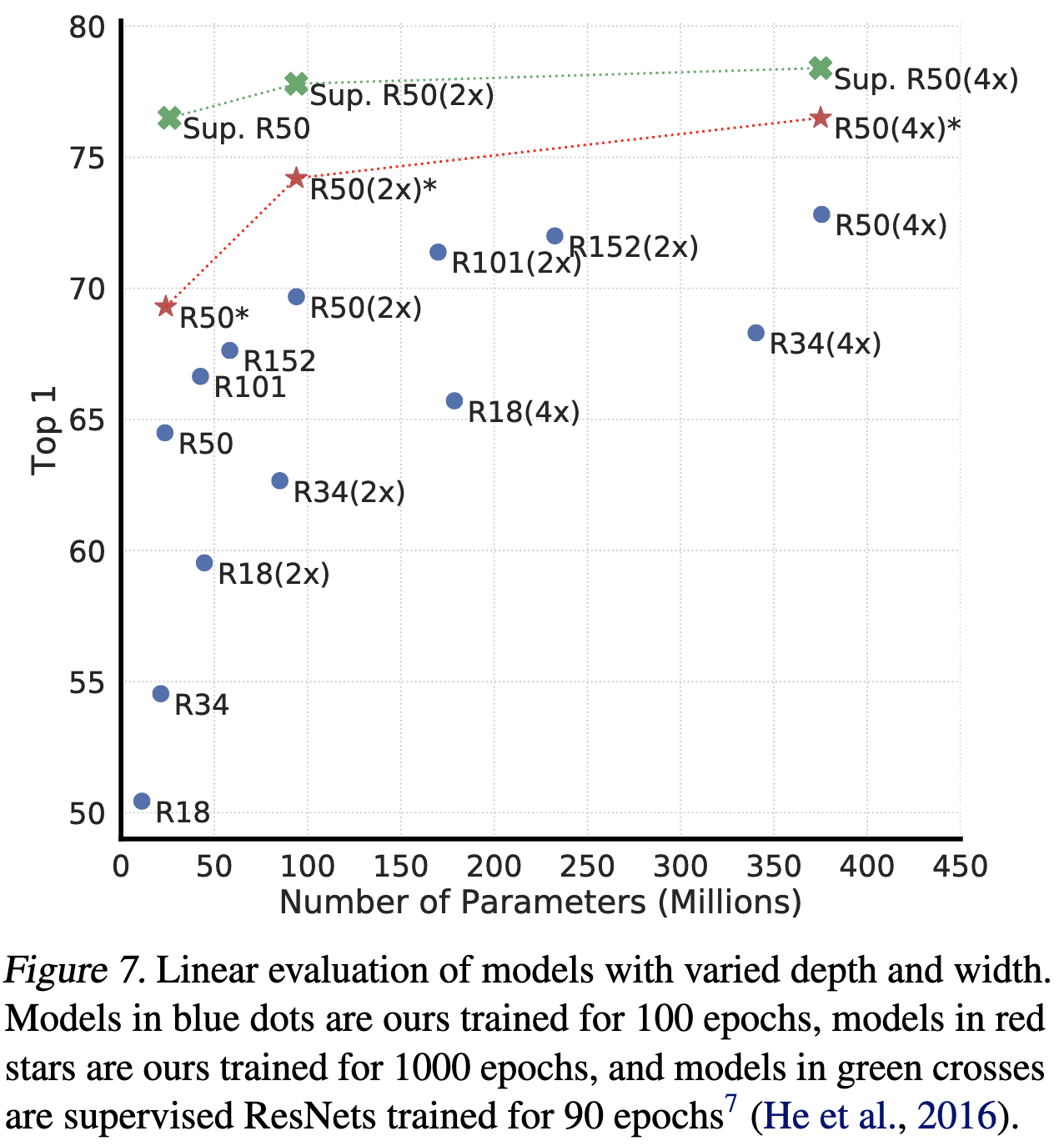
당연하게도 model이 넓고 깊을수록 성능에 영향을 받는다. 아래 그림을 보면 supervised learning보다 contrastive learning이 더 큰 영향을 받는 것을 알 수 있다.
또한 짧게 언급하고 가겠지만 MLP를 이용한 non-linear projection이 linear projection이나 projection하지 않는것 보다 더 성능이 좋았다.
Loss Functions and Batch Size

위 표는 NT-Xent를 주로 사용되는 다른 loss들과 비교한 표다. gradient를 보면 $l_2$는 temperature는 다양한 example에 효과적으로 weight를 부여하며 적절한 $\tau$는 model이 hard negative를 학습 학습하는 것을 도와준다. 또한 cross entropy와 다르게 다른 loss들은 negatives에 reative hardness로 가중치를 부여하지 않는다. 또한 짧게 언급하고 가겠지만 Batch size가 크고 오래 학습할때 contrastive learing은 이점이 있다.
Comparison with State-of-the-art
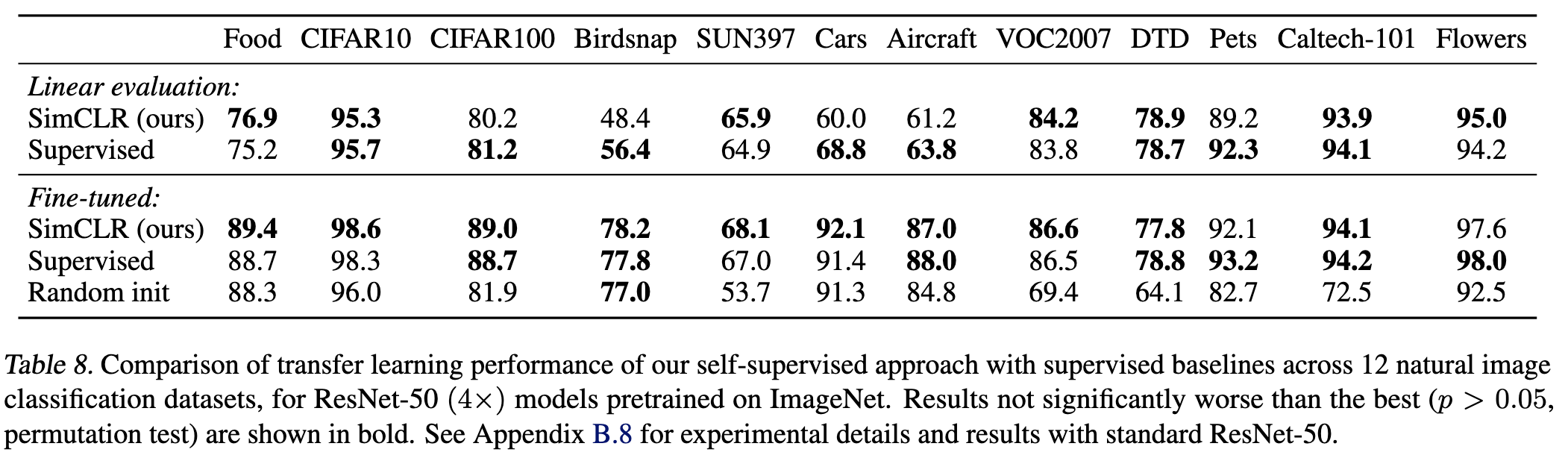
정량 평가 결과는 다음과 같다. 오래된 논문이라 크게 결과에 집중하지 않겠다.
Conclusion
이 논문은 data augmentation, nonlinear head, NT-Xent를 이용한 contrastive visual representation learing을 위한 simple framework를 제안한다. 체계적으로 구성된 실험과 그에 대한 저자의 인사이트가 돋보이는 논문이다.
개인적인 생각
- SimCLR는 오래된 논문이지만 Contrastive learning을 위해 반드시 알아야 하는 논문이라 생각이 들었다. SimCLR의 NT-Xent Loss는 CPC에서 도입한 InfoNCE와 같지만 표기만 조금 다르게 한 Loss로, 1개의 positive와 다수의 negative를 구분하는 (2N-1)-way classification 문제로 self-supervised learning을 한 논문이다. SupCon의 부모 Loss 정도로 생각하면 되며, 이 포스팅을 통해 수식을 정확히 이해할 수 있어서 좋았다.
출처
[1] Wang, Tongzhou, and Phillip Isola. “Understanding contrastive representation learning through alignment and uniformity on the hypersphere.” International conference on machine learning. PMLR, 2020.