[논문리뷰] Supervised Contrastive Learning
NIPS 2020 [Paper] [Github]
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, Dilip Krishnan
23 Apr 2020
Introduction
Cross Entropy(CE)는 딥러닝 분류기의 지도 학습에서 가장 널리 사용되는 loss이다. CE의 문제는 여러 가지가 보고되어 왔는데 저자는 그 중 세가지를 언급하며 서론을 시작한다.
- lack of robustness to noisy labels (노이즈에 약하고, 모델이 잘못된 라벨을 의심하지 않고 그대로 외운다.)
- possibility of poor margins (decision boundary가 샘플에 너무 바짝 붙어 있다.)
- leading to reduced generalization performance (학습에 쓰지 않은 데이터에서 잘 맞추는 능력이 떨어진다.)
그럼에도 불구하고 위 세가지 단점을 커버하는 대부분의 loss는 Large scale dataset(e.g. ImageNet)에서 작동하지 않아서 CE를 계속 사용하게 된다.
최근 몇년간 Contrastive Learning의 부활은 Self-Supervised Learning(SSL)의 눈부신 발전을 이끌었다.Contrastive Learning의 아이디어는 embedding space에서 anchor를 두고 “positive” sample은 당기고 “negative” sample은 밀어버리자는 것이다. SSL에서는 레이블이 없기 때문에 같은 이미지의 다른 view만이 (augmentation을 통해 다른 view를 만든다.) positive sample이 된다. negative sample은 mini batch에서 랜덤하게 샘플링한다.
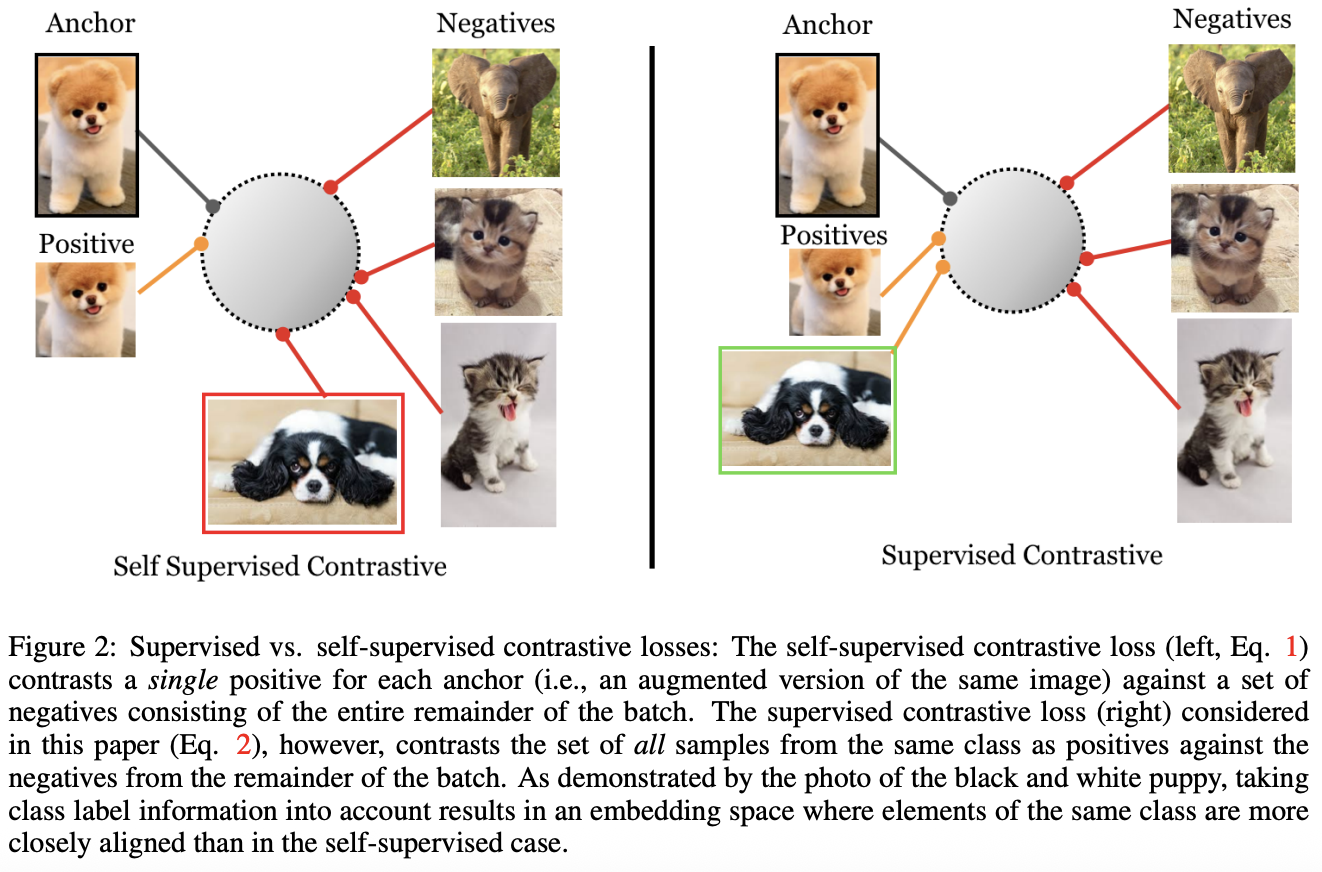
이 논문에서는 레이블 정보를 활용하여 Contrastive SSL에 기반한 지도 학습을 위한 loss를 제안한다. SSL에서는 같은 class더라도 다른 이미지면 negative로 밀어버리는 한계가 있었다. 그러나 SupCond에서는 같은 class에서 나온 Normalized embedding들 끼리는 당기고, 서로 다른 class에서 나온 Normalized embedding끼리는 밀어버린다(Fig. 2 참고). 이 Loss는 triplet Loss와 N-pair Loss의 일반화된 것으로 볼 수 있다. 각 anchor에 많은 positives와 negatives를 사용하는 것으로 hard negative mining(모델을 가장 헷갈리게 만드는 negative만 골라서 집중적으로 학습시키는 전략) 없이 SOTA를 달성 할 수 있었다. 이는 Large scale classification에서 CE보다 더 나은 성능을 보여준 contrastive loss를 Supervised learning에 사용한 첫 사례이다.
Contribution:
- contrastive loss에 anchor 별로 multiple positives를 사용한 novel extension을 제안한다.
- SupCon의 성능은 여러 데이터셋에서 SOTA 급이며 natural corruptions에 robust하다.
- SupCon loss의 gradient가 hard positives and hard negatives로 부터 학습을 장려하는 것을 입증한다.
- CE보다 SupCon이 hyperparameter의 범위에 덜 민감함을 보인다.
Method
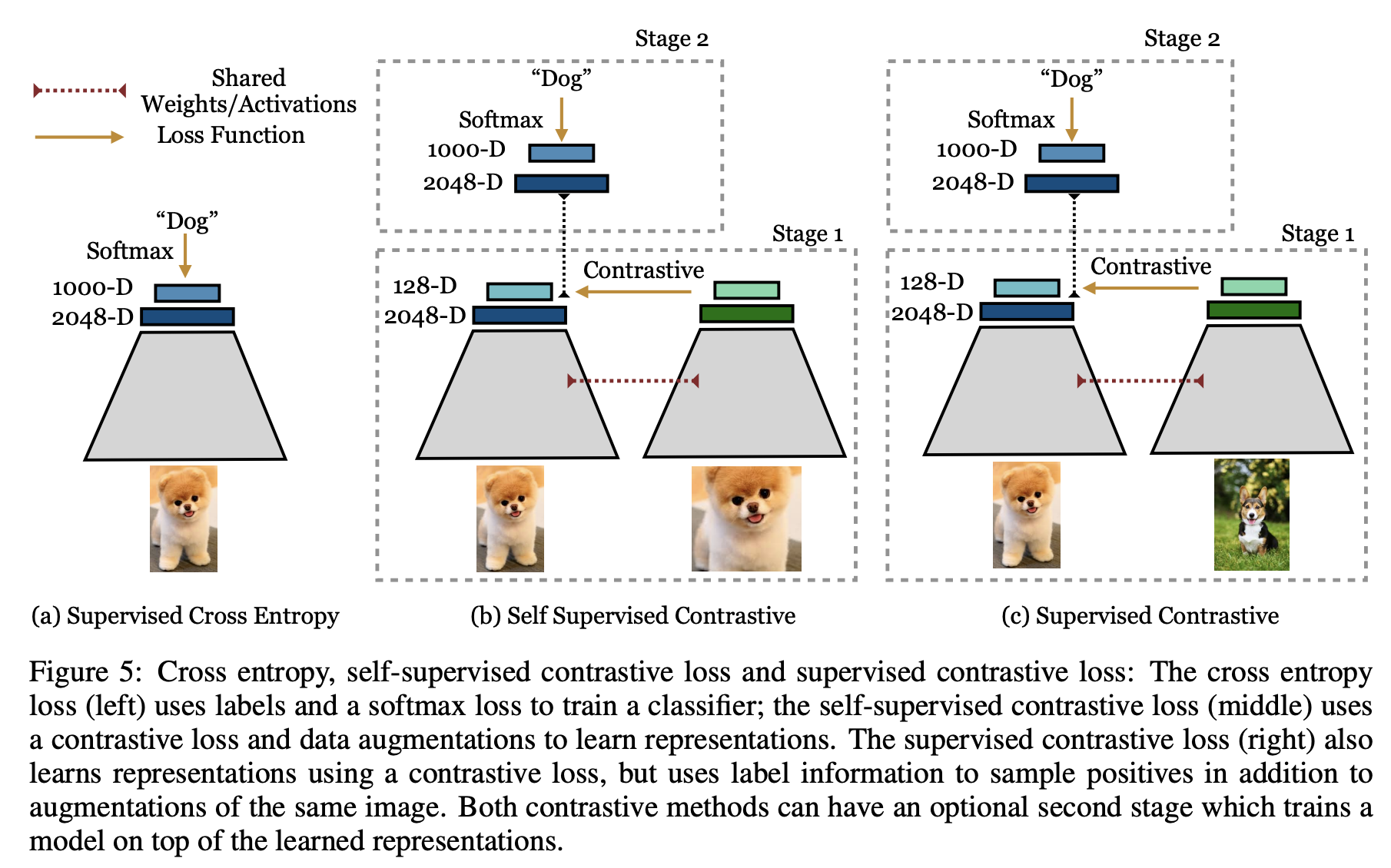
저자들의 방법은 Contrastive multiview coding(CMC) SimCLR에서 쓰인 방법과 유사하다(CMC는 저자가 같고 SimCLR은 구글의 작품이라 구글의 후속 연구라 생각하고 있다.). 학습은 여타 representation learning과 같이 pre-training과 fine-tunning의 two-stage로 이루어진다(fig1. 참고).
- pre-training: 주어진 데이터에 대하여 augmentation을 두번하여 2개의 copy를 얻는다. 같은 encoder에 넣어서 각각 2048 차원(resnet50의 출력 차원)의 normalized embedding을 얻는다. 원활한 loss 계산을 위해 앞에 projection 네트워크를 추가하여 학습하는데 이는 inference시에는 사용하지 않는다.
- fine-tunnig: encoder를 freeze하고 CE를 이용하여 classifier를 학습시킨다.
Representation Learning Framework
- Data Augmentation module, $Aug(\cdot)$: 입력 샘플 $x$에 대하여 random augmentation을 통해 $\tilde{x} = Aug(x)$를 얻는다. 이는 데이터에 대한 2개의 다른 뷰를 의미한다.
- Encoder Network, $Enc(\cdot)$: $D_E = 2048$
$\tilde{x}$를 $\mathbb{R}^{D_E}$ unit hypersphere의 벡터 $r$로 매핑한다. \(\begin{equation} r = Enc(x) \in \mathbb{R}^{D_E} \end{equation}\) - Projection Network, $Proj(\cdot)$: $D_P = 128$
$r$을 $D_P$차원의 MLP나 single linear layer를 이용하여 $z$로 만든다. 이를 다시 normalize 하여 unit hypersphere에 놓이도록 한다. \(\begin{equation} z = Proj(r) \in \mathbb{R}^{D_P} \end{equation}\) Supervised Contrastive Loss를 이해하기 위해 Self-Supervised Contrastive Loss를 알아야 하며 Notation을 알 필요가 있다. batch size를 N이라고 하자, 한 mini batch에는 N개의 랜덤으로 샘플링된 sample, label set이 있을 것이다.
original mini batch는 $\lbrace x_k, y_k \rbrace_{k=1}^{N}$로 표현할 수 있으며
augmentation을 적용한 mini batch는 2N개의 데이터가 있을 것이다. $\lbrace \tilde{x}_l, \tilde{y}_l \rbrace_{l=1}^{2N}$로 표현할 수 있을 것이다. $\tilde{x}_{2k}$와 $\tilde{x}_{2k-1}$은 같은 sample의 서로 다른 view이며 label은 $\tilde{y}_{2k} = \tilde{y}_{2k-1} = y_k$이다.
Self-Supervised Contrastive Losses
multiviewed batch 안에 $i \in I = \lbrace 1, \ldots, 2N \rbrace$은 augmented sample의 index set이라고 하고 $j(i)$는 같은 sample의 다른 view라고 할 때 Self-Supervised Contrastive Loss는 다음과 같이 표현할 수 있다. \(\begin{equation} \mathcal{L}^{\text{self}} = \sum_{i \in I} \mathcal{L}^{\text{self}}_i = -\sum_{i \in I} \log \frac{ \exp\left( z_i \cdot z_{j(i)} / \tau \right) }{ \sum_{a \in A(i)} \exp\left( z_i \cdot z_a / \tau \right) } \end{equation}\) $z_l = Proj(Enc(\tilde{x})) \in \mathbb{R}^{D_P}$이고 $\cdot$은 내적을 의미한다. $\tau \in \mathbb{R}^+$는 scalar temperature parameter다. 마지막으로 $A(i) \equiv I \setminus \lbrace i \rbrace$ index $i$는 anchor로 부르며, index $j(i)$는 positive, 나머지 2(N-1)개를 negatives라고 정의한다.
Supervised Contrastive Losses
기존의 Contrastive Loss에서 레이블 정보를 추가해줘야 하기 때문에 아래의 3, 4번 수식 처럼 변경을 해야 한다. $P(i) \equiv \lbrace p \in A(i): \tilde{y}_p = \tilde{y}_i \rbrace$는 multiviewed batch에서 모든 positives의 index set이며 $\vert P(i) \vert$는 cardinality(집합의 원소 개수)이다.
\[\begin{equation} \mathcal{L}^{\text{sup}}_{\text{out}} = \sum_{i \in I} \mathcal{L}^{\text{sup}}_{\text{out}, i} = \sum_{i \in I} \frac{-1}{\vert P(i) \vert} \sum_{p \in P(i)} \log \frac{ \exp\left( z_i \cdot z_p / \tau \right) }{ \sum_{a \in A(i)} \exp\left( z_i \cdot z_a / \tau \right) } \end{equation}\] \[\begin{equation} \mathcal{L}^{\text{sup}}_{\text{in}} = \sum_{i \in I} \mathcal{L}^{\text{sup}}_{\text{in}, i} = \sum_{i \in I} - \log \left( \frac{1}{\vert P(i) \vert} \sum_{p \in P(i)} \frac{ \exp\left( z_i \cdot z_p / \tau \right) }{ \sum_{a \in A(i)} \exp\left( z_i \cdot z_a / \tau \right) } \right) \end{equation}\]위 두 Loss 전부 다음의 성질을 갖춘다.
- Generalization to an arbitary number of positives: 평균적으로 batch당 N/C개의 추가 positive가 생성된다. (C: number of classes)
- Contrastive power increases with more negatives: Denominator의 negative summation 유지로 더 많은 negative를 활용 가능하며 Noise contrastive estimation(NCE)과 N-pair loss의 이점 계승한다.
- Intrinsic ability to perform hard positive/negative mining: Normalized representation 사용 시 hard positive/negative에 대한 gradient 자동 증폭되며 Explicit hard mining 없이도 효과적인 학습 가능하다.
두 Loss가 겉보기에는 같아보일지라도 Log 함수가 concave function(오목한 함수)이기 때문에 Jensen’s inequality로 인하여 이론상 $\mathcal{L}^{\text{sup}}_{\text{in}} \leq \mathcal{L}^{\text{sup}}_{\text{out}}$ 이며 실제로도 ImageNet top-1 accuracy에서 각각 67.4%와 78.7%로 $\mathcal{L}^{\text{sup}}_{\text{out}}$ 가 더 성능이 좋았다.(이 부분에 대한 수학적 유도를 본문 3.2.2 후반부와 Supplementary 6장에서 제공하나, 본 post에서는 다루지 않겠다.)
4. Experments
본 논문에서는 SupCon Loss의 성능을 CIFAR-10, CIFAR-100, ImageNet 데이터셋에서 accuracy를 비교했으며, common image corruption에 대한 강건성을 증명하기 위해 ImageNet-C 데이터셋에서도 검증도 했다. 하이퍼 파라미터와 데이터 감소에 따른 성능 변화도 보여준다.
인코더는 보통 자주 쓰이는 resnet-50,101,200($D_E = 2048$) 세가지를 통해 비교했으며 Augmentation 전략으로는 AutoAugment, RandAugment, SimAugment, Stacked RandAugment 네가지를 사용했으며 resnet-50에서 SupCon과 CE 모두에서 AutoAugment 전략이 가장 성능이 좋았다. Stacked RandAugment는 resnet-200에서 성능이 제일 좋았다. (자세한 성능은 아래의 table 참고)
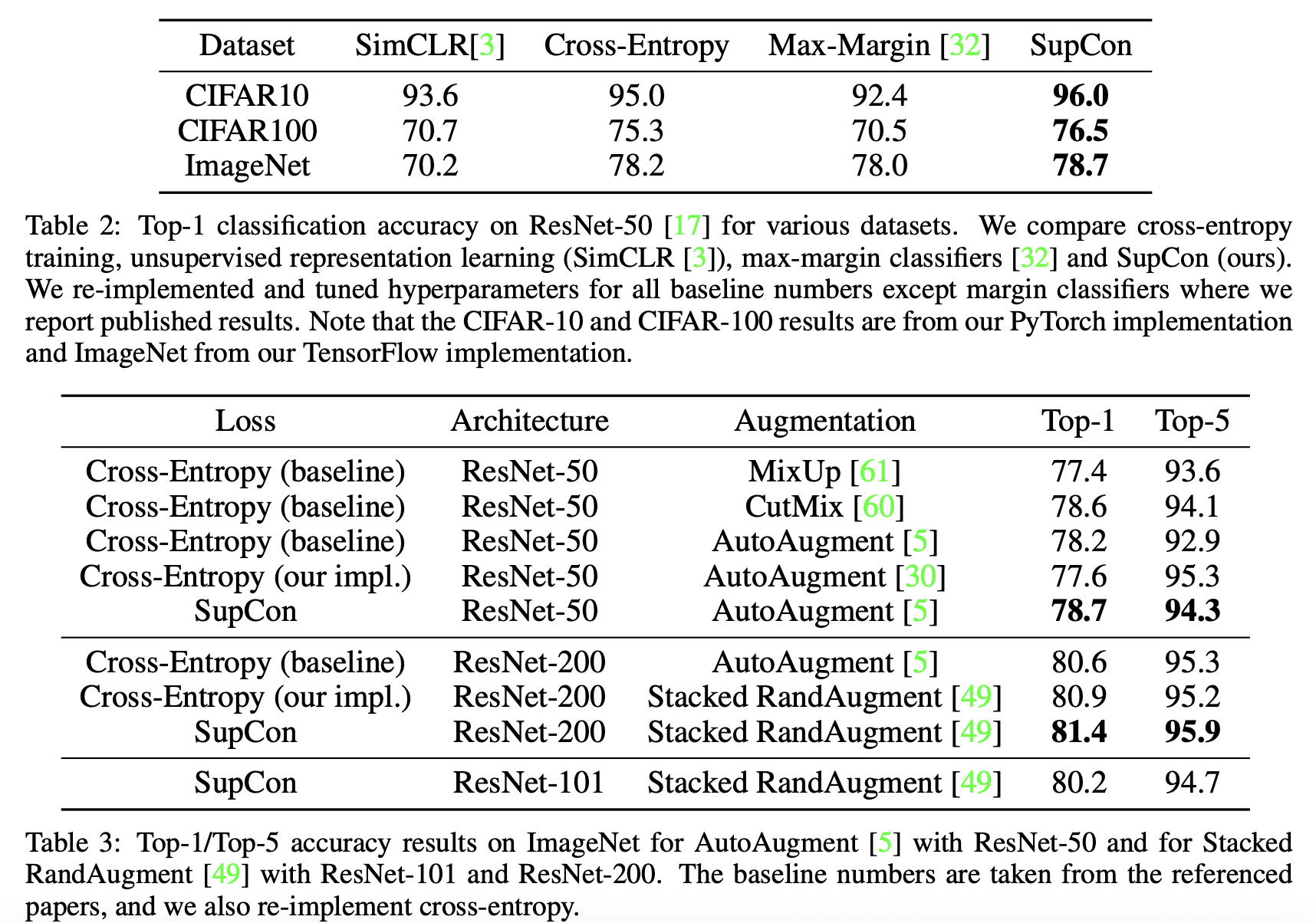
저자들은 MoCo 같이 memory based 방법도 실험해봤다. 8,192개의 queue, N=256, SGD optimizer의 조건에서 원래 방식에서 N=6144일 때 보다 조금 더 나은 79.1%의 성능을 보였다.
SupCon은 sample 당 2개의 augmented view를 사용하기 때문에 2N의 batch size를 가지게 된다. 따라서 CE의 batch size를 2N으로 설정하여 실험했고 77.5%의 성능을 달성했다.
N-pairs loss도 N=6144로 실험했지만 57.4%로 성능이 좋지는 않았다. 저자들은 SupCon이 multiple views, lower temperture 그리고 더 많은 positives를 사용했기 때문에 더 나은 결과를 달성했다고 설명한다.

저자들은 ImageNet-C 데이터셋에서 노이즈에 얼마나 강건한 결과를 보이는지 실험을 했고 위 그림의 결과를 얻었다.
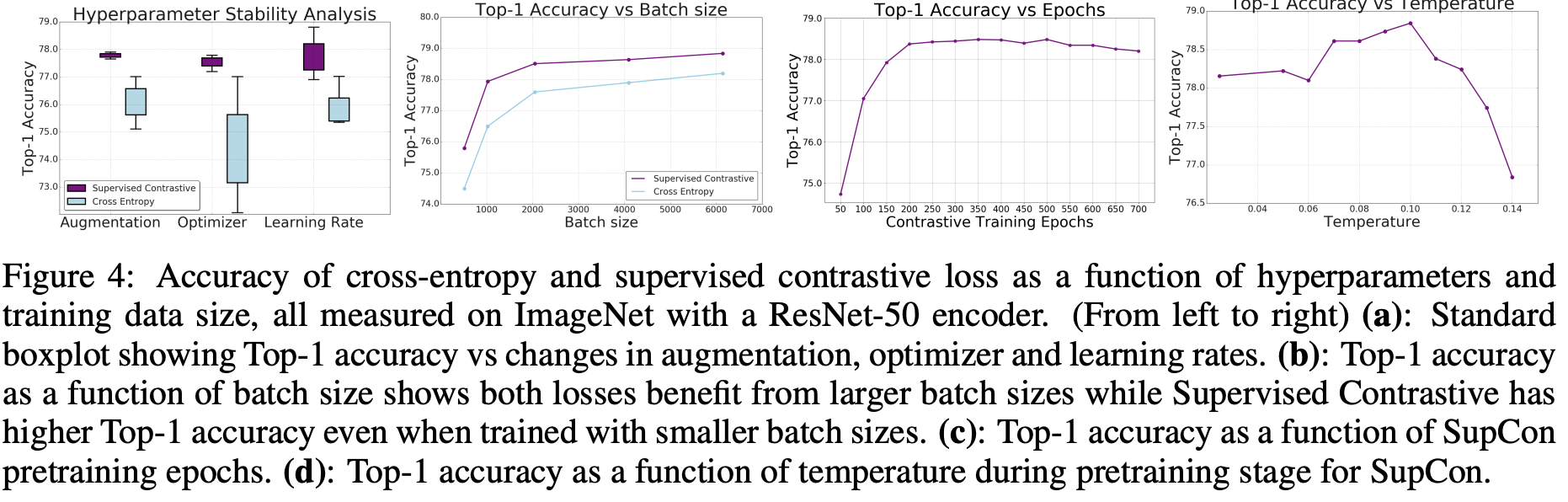
위 그림은 augmentations, optimizers and learning rates의 다양한 hyperparameter에 대하여 같은 batch size에서 CE와 비교한 결과이다. SupCon은 hyperparameter에 크게 구애받지 않고 안정적인 모습을 보여준다.
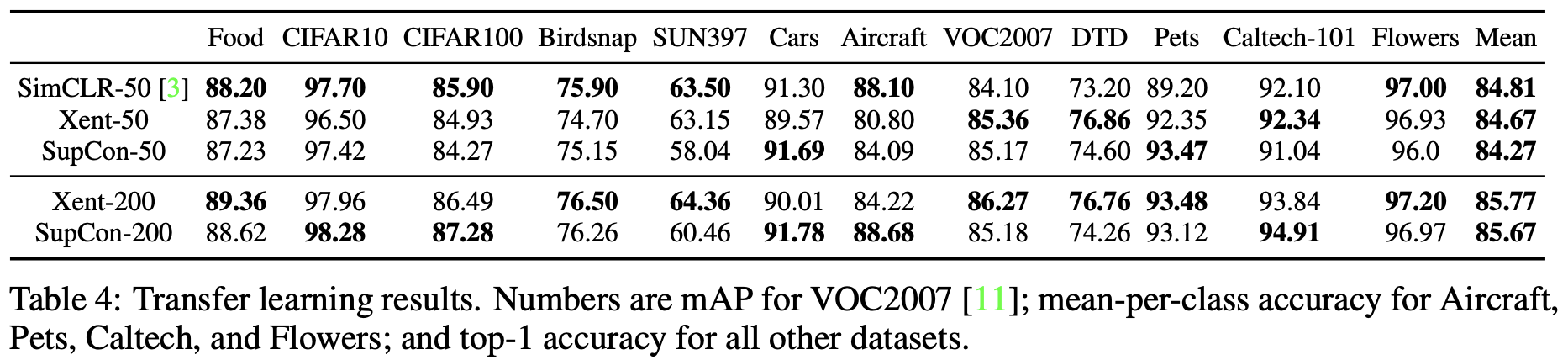
마지막으로 위 그림은 다양한 데이터셋에 대한 transfer learning의 결과이다.
특이하게도 이 논문은 discussion 없이 Training Details와 함께 글을 마무리한다. SupCon은 ResNet-200 모델은 700 epochs 학습하였으며 그보다 작은 모델에 대해서는 350 epochs 학습시켰다.(최소 200 epochs은 학습해야 한다.)
linear classifier는 필수가 아니며 이는 top-1 accuracy를 파악하기 위해 사용한 것이다. representation learning이나 transfer learning에는 당연히 필요 없다. 또한 반드시 two stage로 나눠서 학습 할 필요는 없다. linear classifier에서 encoder로 gradient 전파되는 것을 막으면 한번에 학습도 가능하다. 성능도 별 차이 없지만 저자들은 SupCon Loss의 효과를 분리하기 위해 일부러 two stage로 학습했다.
대부분의 경우에서 N=2048 수준에서 충분했지만 6144까지 올린 이유는 negative 증가로 인해(분모가 커짐) hard positive(비슷한 feature를 제공하는 easy positive는 loss에 기여가 더 적다.)에 대한 gradient가 강화되어 성능이 조금 더 오를 수 있기 때문이다. 다만 같은 배치 조건에서도 SupCon은 cross-entropy보다 더 큰 learning rate를 허용한다.
$\tau = 0.1$로 잡은 이유는 작은 temperature가 주는 이점이 있기 때문이다. 그럼에도 너무 작은 temperature는 gradient가 불안정하다(fig 4 참고).
마지막으로 저자는 pre-training 단계와 classifier training 단계에서 다양한(LARS, RMSProp, SGD + momentum) optimizer를 조합해서 실험했다. ResNet을 cross-entropy로 학습할 때는 SGD with momentum이 가장 좋았으나, ImageNet에서 SupCon을 사용할 경우 사전학습에는 LARS, 선형 분류기 학습에는 RMSProp이 가장 높은 성능을 보였다. 반면 CIFAR10/100과 같은 소규모 데이터셋에서는 SGD with momentum이 가장 효과적이었다.
개인적인 생각
- Contrastive Loss를 Supervised Learning 학습 환경에서 적용시켜 성공한 최초의 사례이다. positives를 이용한 덕분에 hard positives와 hard negatives를 잘 분류할 수 있었으며 일반 CE보다 나은 성능을 보였다. 다만 MoCo의 queue를 사용하지 않으면 6144라는 큰 batch가 필요하며, 의료 인공지능을 연구하는 입장에서 fine grained morphology와 tail dataset에 대한 성능 비교가 없었으며 추후 연구에 의하면 효과가 크지 않은 것이 입증된 부분이 limitation이다. 이 부분은 앞으로 다룰 BCL, BPaCo 등 후속 연구에서 개선되었다.