[논문리뷰] UWT-Net: Mining low-frequency feature information for medical image segmentation
MICCAI 2025 [Paper] [Github]
Zhang Pengcheng, Ouyang Xiaocao, Peng Ran
23 Sep 2025
Introduction
Medical image segmentation은 의료 이미지 프로세스에서 중요한 연구 방향이다. 딥러닝의 빠른 발전과 컴퓨터를 이용한 진단의 대중화와 함께 많은 연구가 딥러닝 medical image segmentation에 집중되고 있다. 이 분야는 U-Net, U-Net++ 등 많은 CNN 기반 방법이 개발되었다. 그러나 CNN은 global dependency를 modeling하는 것에 한계가 있다.
이 부분은 Transformer가 도입이 되며 관련없는 배경 정보를 억제하며 대상 지역에 자동으로 집중할 수 있는 attention을 이용한 Att-Unet과 TransUNet, Swin-UNet등이 CNN의 단점을 보완하며 좋은 결과를 내왔다.
Wavelet transform 역시 medical image segmentation에서 많은 결과를 냈던 방법이다. U-Net 아키텍처에 wavelet transform과 converter module을 통합하여 비인두암 segmentation의 정확성과 모델 견고성을 높인 연구도 있고, DTCWT와 iDTCWT를 down-sampling과 up-sampling에 도입한 spectral U-Net도 있다. 그러나 지금까지 존재한 방법은 저주파 정보에 집중을 하지 못했고 이를 마이닝하여 활용하지 못하는 것으로 나타났다. 저주파 정보는 global context와 공간 구조를 담고 있는데, 이 정보는 전체적인 모양과 위치, 장기나 조직의 공간적인 관계를 이해하는데 돕기 때문에 segmentation task의 결정적이고 중요한 단서를 제공한다. 도욱이 down sampling 시에 고주파 정보는 흐릿한 경계와 함게 쉽게 날라간다. 저주파 특징 정보의 유지 및 활용은 정보의 손실을 줄여 정확도를 높일 수 있다. 더욱이 저주파 정보는 노이즈에 덜 예민하기 때문에 강건성을 강화할 수도 있다.
본 논문에서는 위의 문제를 인지하고 WTconv에 영감을 받아 Image Multi-Frequency Information Extraction(IMFIE) block을 제안한다. 이 블록은 표준 Convolution과 WTconv의 장점을 결합하여 medical image segmentation에서 저주파 정보를 극대화하고 활용할 수 있도록 한다.
Method
아래 그림은 UWT-Net의 전체 구조이다. encoder에서는 IMFIE 블록이 feature를 뽑으며 해상도의 절반을 줄이는 반면 decoder에서는 해상도를 두배로 올려 복구한다.
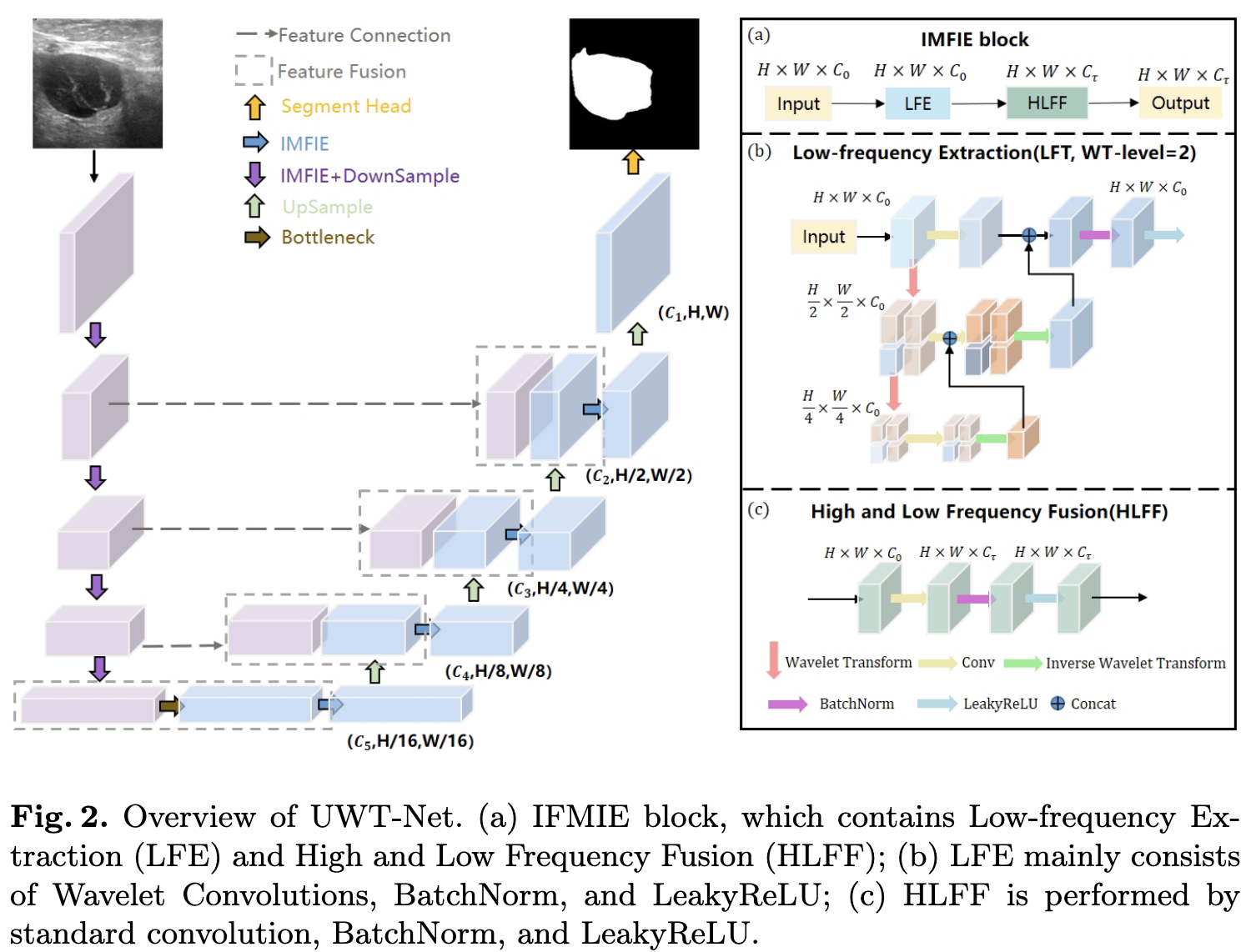
Wavelet Convolutions
Wavelet Convolutions은 WTconv 처럼 효율적이고 간단한 Haar WT를 사용한다. 또한 해당 논문의 4가지 필터를 그대로 사용하는데 정의는 다음과 같다. \(\begin{aligned} F_{LL} &= \frac{1}{2} \begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix}, \quad F_{LH} = \frac{1}{2} \begin{bmatrix} 1 & -1 \\ 1 & -1 \end{bmatrix}, \\ F_{HL} &= \frac{1}{2} \begin{bmatrix} 1 & 1 \\ -1 & -1 \end{bmatrix}, \quad F_{HH} = \frac{1}{2} \begin{bmatrix} 1 & -1 \\ -1 & 1 \end{bmatrix} \end{aligned} \tag{1}\) $F_{HH}$ , $F_{LH}$, $F_{HL}$은 고주파 필터 셋이고 $F_{LL}$는 저주파 필터이다. 위 필터로 convolution 연산을 한 후에는 4개의 채널이 생기고 이들의 해상도는 절반으로 줄어든다.
\(\begin{equation} [N_{LL}, N_{LH}, N_{HL}, N_{HH}] = Conv([F_{LL} F_{LH}, F_{HL}, F_{HH}], N) \end{equation}\) $N_{HH}$ , $N_{LH}$, $N_{HL}$은 각각 대각, 수직, 수평의 고주파 요소이며 $N_{LL}$은 저주파 요소이다. $F_{HH}$ , $F_{LH}$, $F_{HL}$는 각각 orthonormal basis이기 때문에 transposed convolution은 IWT이다. \(\begin{equation} N = Conv-transposed([F_{LL} F_{LH}, F_{HL}, F_{HH}],[N_{LL}, N_{LH}, N_{HL}, N_{HH}]) \end{equation}\)
cascade wavelet decomposition은 $X_{LL}$에 재귀적으로 WT하며 얻을 수 있다. \(\begin{equation} N^{(i)}_{LL}, N^{(i)}_{LH}, N^{(i)}_{HL}, N^{(i)}_{HH} = WT(N^{(i-1)}_{LL}) \end{equation}\) $N^{(0)}_{LL}=N$ 이며 $i$는 현재 level이다. 이를 통해 주파수 분해능이 증가하고 낮은 주파수에 대한 공간 분해능이 감소하게 된다.
wavelet domain의 convolution은 다음과 같이 구현된다.
- WT를 사용하여 입력 저주파수 및 고주파수 요소를 필터링하고 축소한다.
- 각각의 주파수 맵을 채널별로 convolution을 한다.
- IWT를 사용하여 결과를 출력한다.
N은 입력 텐서고 W는 입력 채널의 4배의 수를 가진(LL, HH, HL, LH 각각) k×k depth-wise kernel이다.
\[\begin{equation} N^{(i)}_{H},\; N^{(i)}_{LL} = \mathrm{WT}\!\left(N^{(i-1)}_{LL}\right) \end{equation}\] \[\begin{equation} M^{(i)}_{H},\; M^{(i)}_{LL} = \mathrm{Conv}\!\left( W^{(i)},\; \left(N^{(i)}_{LL},\, N^{(i)}_{H}\right) \right) \end{equation}\]$N^{(0)}$은 layer의 입력이며 $N^{(i)}_{H}$는 2개의 고주파수 맵이며 $i$는 level이다. WT와 그의 역은 선형 연산이라 서로 다른 주파수의 출력은 다음과 같이 합할 수 있다.
\[\begin{equation} L^{(i)} = \mathrm{IWT}\left( M^{(i)}_{LL} + L^{(i+1)},\; M^{(i)}_{H} \right) \end{equation}\]다양한 level의 convolution을 합산한 결과이다.$L^{(i)}$는 $i$부터 집계된 츨력이며 서로 다른 크기의 convolution의 두 출력이 합산되어 출력된다.
UWT-Net Architecture
각 IMFIE block은 다음의 요소로 구성된다.
- WTConv
- Conv
- Batch normalization layer(BN)
- Leaky ReLU(LR)
이미지 $I \in \mathbb{R}^{H_0 \times W_0 \times C_0}$이 주어졌을때 수식은 다음과 같이 작성할 수 있다.
\[\begin{equation} O=LR(BN(WTConv(I))) \end{equation}\] \[\begin{equation} O_\tau=LR(BN(Conv(O))) \end{equation}\]$O_\tau \in \mathbb{R}^{H^\prime \times W^\prime \times C_\tau}$를 얻을 수 있고, $C_\tau$는 model의 scale에 따라 정의된다.
UWT-Net Encoder는 IMFIE 후에 feature의 해상도를 반으로 줄이기 위해 Maxpool을 적용한다.
\[\begin{equation} E_\tau = LR(MP(IMFIE(E_{\tau-1}))) \end{equation}\]Bottleneck 구조는 deep feature representation을 학습하기 위해 차원과 해상도를 변경하지 않고 표준 convolution을 사용한다.
UWT-Net Decoder는 $\tau$번째 encoder의 $E^\prime_\tau$ feature 데이터와 decoder의 $D^\prime_\tau$를 concat하기 위해 IMFIE 이후 Upsample(US)하여 채널을 맞춰 준다. 수식으로는 다음과 같이 표현한다. \(\begin{equation} D_\tau = Cat(E_{\tau}^\prime,D_{\tau}^\prime) \end{equation}\) \(\begin{equation} D_{\tau-1} = LR(US(IMFIE(D_\tau))) \end{equation}\)
final segmentation map은 0번째 layer에서 $D_0 \in \mathbb{R}^{H_0 \times W_0 \times C_Y}$로 구성되며 $C_Y$는 label의 갯수이다. T를 GT라고 했을때 loss는 pixel-wise CE를 사용하여 다음과 같이 표현한다. \(\begin{equation} L_{seg}=CE(T,UWT-Net(I)) \end{equation}\)
전반적으로 이런 네트워크 설계는 U-Net의 장점을 계슨하면서 표준 convolution에 의한 저주파 정보 약화를 보완할 수 있다. 저주파와 고주파 정보를 융합함으로 모델은 global structure와 local detail의 균형을 더 잘 맞출 수 있다. IMFIE로 인해 receptive field가 증가되는데 이는 feature extraction 능력과 일반화 능력을 더욱 상승시키기 때문에 모델의 성능을 더 높일 수 있다.
Experiment
저자는 효과와 강건성 일반화 능력을 실험하기 위해 BUSI, GlaS, CVC-ClinicDB까지 총 3개의 데이터셋으로 실험을 했으며 공정한 비교를 위해 사전 연구와 같은 setup으로 실험했다.
optimizer: Adam
lr: 1e-3 (cosine annealing lr 1e-4)
loss: BCE+dice
metric: IoU, F1 score
augmentation: random rotation, flipping
batch size: 8
train/val : 8/2
from scratch
각 실험에 대하여 3번씩 반복하여 std와 평균을 함께 보고했으며 결과는 다음과 같다.
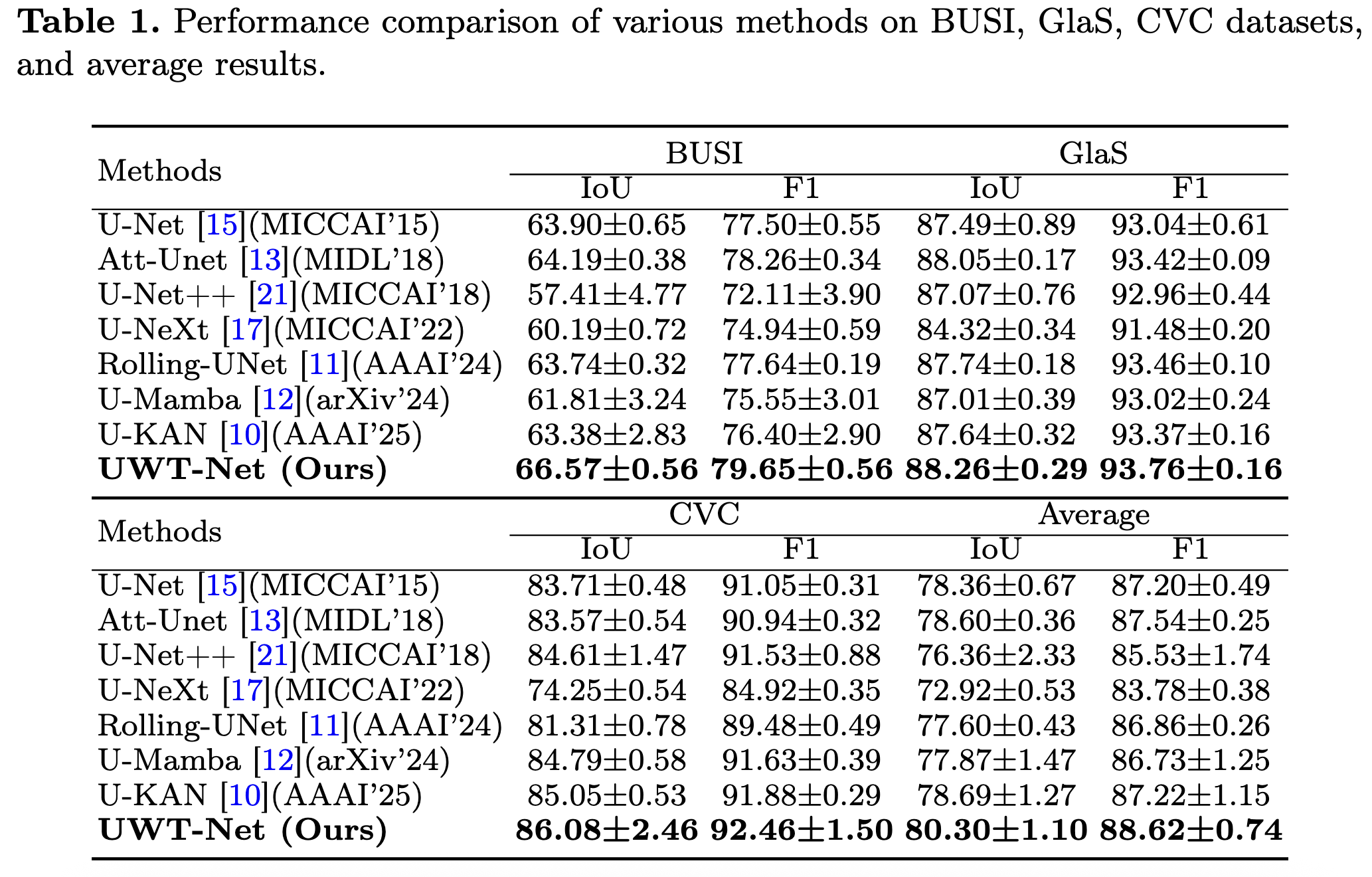

U-Net, U-Net++, U-Mamba, U-NeXt, Rolling-UNet 그리고 SOTA인 U-KAN을 비교한 결과 데이터셋에서 좋은 일반화 성능과 강건성을 보이며 SOTA를 달성했다.
저자는 IMFIE의 효과, WT-level, model scale에 대하여 ablation study를 진행했으며 결과는 다음과 같다.

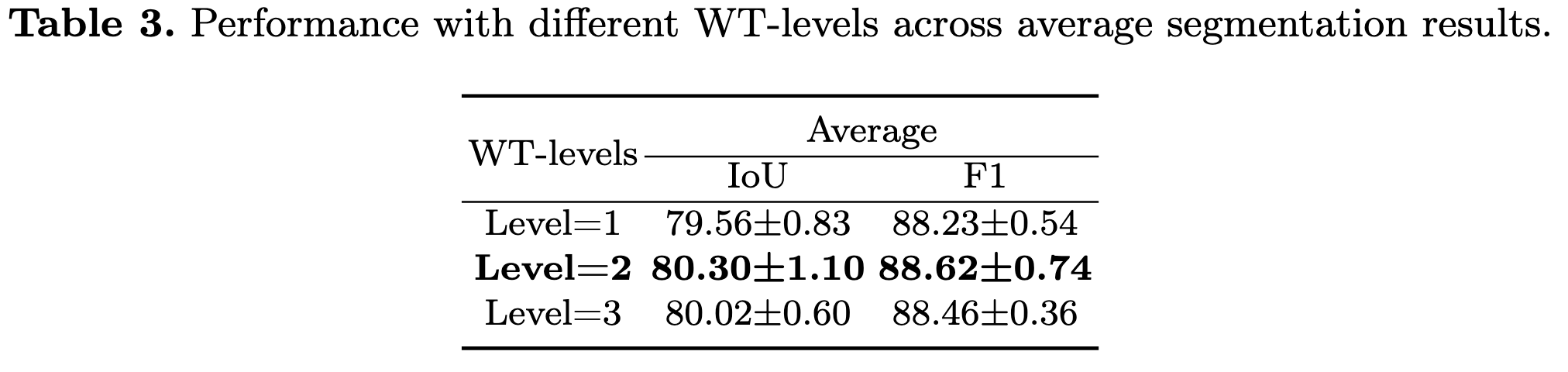
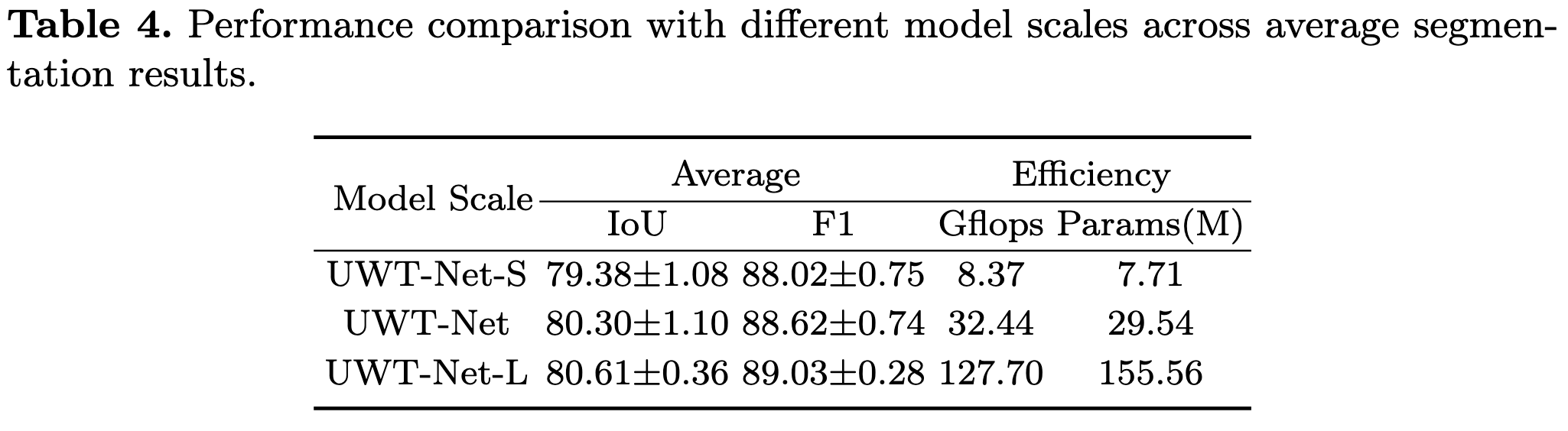
Conclusion
이 논문에서 저자들은 medical imaging 분야에서 덜 활용되어 왔던 저주파 feature의 잠재력을 탐구하며 IMFIE block과 UWT-Net을 제안한다. 결과는 해당 모델이 효과적으로 저주파 정보를 마이닝하고 사용하여 이를 medical image의 고주파 정보와 융합하여 segmentation 효과를 향상시킬 수 있음을 보여준다.
개인적인 생각
wavelet convolution의 아이디어를 의료 도메인의 적용하여 성공적으로 segmentation을 성공한 사례이다. 다만 ViT를 활용한 모델과 비교가 없어서 global하게 보는 model끼리 비교가 잘 안된것 같고, 필자가 관심있어하는 CT나 MRI 같은 도메인에서의 비교가 없어서 약간은 아쉽다는 생각이 들었다.
여담으로 해당 논문은 open review를 지원하는 2025년 MICCAI 학회에서 발표된 논문이다. open review를 보니 비영어권 공학자들이라 그런지 영어 관련 지적이 있었는데 나보다 영어 논문을 더 많이 읽은 사람도 영어가 어렵구나 싶다. 그래도 괜찮다. 우리의 first language 는 engineering이니까…