[논문리뷰] Wavelet Convolutions for Large Receptive Fields
ECCV 2024 [Paper] [Github]
Shahaf E. Finder , Roy Amoyal , Eran Treister , and Oren Freifeld
15 Jul 2024
Introduction
지난 10년간 CV 분야는 CNN이 지배를 했었다. 그러나 ViT의 등장으로 CNN은 저물어가는 추세다. CNN의 convolution이 local feature만 섞어서 처리하는 반면 ViT의 multi-head self-attention은 이미지의 모든 spatial position에서 나온 feature들을 한 번에 섞어서 처리한다. 이 CNN과 ViT의 gap을 줄이기 위해서 다양한 연구가 있어왓지만 보통 7×7 이상의 커널을 사용할 경우 성능이 포화되거나 오히려 줄어드는 경향을 보여왔다. RepLK는 31×31, SLaK는 51×51까지 kernel을 확장했으나, 파라미터 수가 quadratic하게 증가하여 over-parameterization 문제가 발생했다. RepLK에서 발견된 흥미로운 속성 중 하나는 큰 커널을 사용할 수록 CNN은 shape-biased 된 것을 확인한 것이다. 이는 저주파를 잡아내는 성능이 향상 된 것이다. 이것은 꽤 놀라운 발견인데 왜냐하면 CNN은 보통 고주파 영역을 잡아내는 경향이 있기 때문이다(참고로 저주파=이미지의 전체적인 모양, 고주파=엣지).
저자들은 이 현상을 보며 “신호처리 도구를 이용해 over-parametrization 없이 convolution의 receptive field(RF)를 확장할 수 있을까?” 라는 질문을 한다. 이 논문에서는 time-frequency analysis 도구인 Wavelet transformation(WT)을 이용해서 convolution의 RF를 확장하고 cascading을 통해 CNN이 저주파에도 잘 반응하도록 만든다. WT는 Fourier transformation(FT)와 달리 공간적 해상도를 유지하여 spatial operation인 convolution이 더욱 의미있게 한다. cascading을 사용함으로 k×k RF를 사용할때 O(log k)만큼의 학습 가능한 파라미터가 필요하다. 때문에 큰 RF에 대하여 quadratic하게 파라미터 수가 증가했던 기존 연구들보다 효율적이다.
저자들이 요약한 Contribution
- convolution의 receptive field를 효율적으로 증가시킨 WTConv 도입함.
- drop-in replacement로 디자인되어 어떤 CNN에서도 간단하게 바꿀 수 있음.
- 방대한 양의 검증으로 CNN보다 더 나은 결과를 보임을 시연함.
- CNN의 확장성, robustness, shape-bias, ERF(Effective Receptive Fields)에 대하여 분석함
Method
글쓴이의 추가 설명!
Method에 들어가기 앞서 “WT란 무엇이며 FT는 왜 안되는가”에 대한 설명을 하고 싶다. 설명의 대상은 이미지 도메인에서 주파수가 가지는 의미를 알아야 하는데, 저주파는 “전반적인 형태”에 관한 정보를 가지게 되고, 고주파는 특정 패턴/엣지 등의 정보를 가지게 된다.
우선 FT는 입력 신호 전체를 sin/cos 파동들의 합으로 분해하는 Transform이다. FT를 하게 되면 주파수 성분만 가지고 있어서 이 주파수가 이미지의 어디 부분에서 나타났는지 알 수 없다. spatial information 손실은 spatial operation인 convolution 연산에서 한계가 클 수 밖에 없다.
WT는 그 부분을 완벽하게 커버한다. WT는 입력 신호를 여러 크기의 “작은 파동(wavelet)”으로 분해하는 Transform이다. 어떤 주파수가 어디에 있는지 Spatial resolution을 어느 정도 유지할 수 있다는 장점이 있다.
본문에서는 Haar WT를 사용한다. 주어진 이미지 X에 대해, 한 공간 차원(가로 또는 세로) 에서의 1-level Haar WT은 커널 $\frac{1}{\sqrt{2}}[1,1]$와 $\frac{1}{\sqrt{2}}[1,-1]$ 를 사용한 채널별(depth-wise) 컨볼루션을 먼저 수행한 뒤, 2배 다운샘플링을 적용하는 것으로 정의된다. 2D Haar WT를 수행하기 위해 둬 차원을 결합하여 다음과 같은 4개의 커널을 사용한다.
\[\begin{aligned} f_{LL} &= \frac{1}{2} \begin{bmatrix} 1 & 1 \\ 1 & 1 \end{bmatrix}, \quad f_{LH} = \frac{1}{2} \begin{bmatrix} 1 & -1 \\ 1 & -1 \end{bmatrix}, \\ f_{HL} &= \frac{1}{2} \begin{bmatrix} 1 & 1 \\ -1 & -1 \end{bmatrix}, \quad f_{HH} = \frac{1}{2} \begin{bmatrix} 1 & -1 \\ -1 & 1 \end{bmatrix} \end{aligned} \tag{1}\]$f_{LL}$은 저주파 필터이고 $f_{LH}$, $f_{HL}$, $f_{HH}$는 고주파 필터의 set이다. 각각 세로, 가로, 대각의 요소를 필터링한다. 각 채널에 대하여 output은 다음과 같이 나온다.
\[\begin{equation} [X_{LL}, X_{LH}, X_{HL}, X_{HH}] = Conv([f_{LL} f_{LH}, f_{HL}, f_{HH}], X) \end{equation}\]결과는 4개의 채널을 가지게 되며 stride가 2이기 때문에 각각 X의 절반의 해상도를가진다. 각 커널은 직교 기저이기 때문에 역변환인 IWT는 transposed convolution을 취해서 쉽게 얻을 수 있다. \(\begin{equation} X = Conv-transposed([f_{LL} f_{LH}, f_{HL}, f_{HH}],[X_{LL}, X_{LH}, X_{HL}, X_{HH}]) \end{equation}\) 그리고 cascade wavelet decomposition은 $X_{LL}$에 재귀적으로 WT하며 얻을 수 있다. \(\begin{equation} X^{(i)}_{LL}, X^{(i)}_{LH}, X^{(i)}_{HL}, X^{(i)}_{HH} = WT(X^{(i-1)}_{LL}) \end{equation}\) $X^{(0)}_{LL}=X$ 이며 $i$는 현재 level이다. 이를 통해 주파수 분해능이 증가하고 낮은 주파수에 대한 공간 분해능이 감소하게 된다.
이제 WT와 IWT가 동작하는 방식을 확인했으니 wavelet domain에서 convolution이 어떻게 이루어지는지 확인할 차례다. 앞서 말했듯이 큰 convolution layer에는 quadratic한 파라미터가 필요하다. 이를 해결하기 위해 저자들은 다음 방법을 제시한다.
- 필터에 WT를 적용하여 입력의 저주파와 고주파를 필터링한다.
- IWT로 출력을 구성하기 전에 필터링 된 서로 다른 주파수 맵에 small-kernel depth-wise convolution을 한다. \(\begin{equation} Y = IWT(Conv(W, WT(X))) \end{equation}\) 로 간단하게 표기할 수 있다. W는 k×k depth-wise kernel이다. 이 연산을 적용하게 되면 여러 주파수 성분간의 convolution을 할 수 있을 뿐 아니라 작은 kernel로 하여금 original input의 더 넓은 범위를 계산 할 수 있게 한다. 아래의 그림이 이를 잘 설명한다.
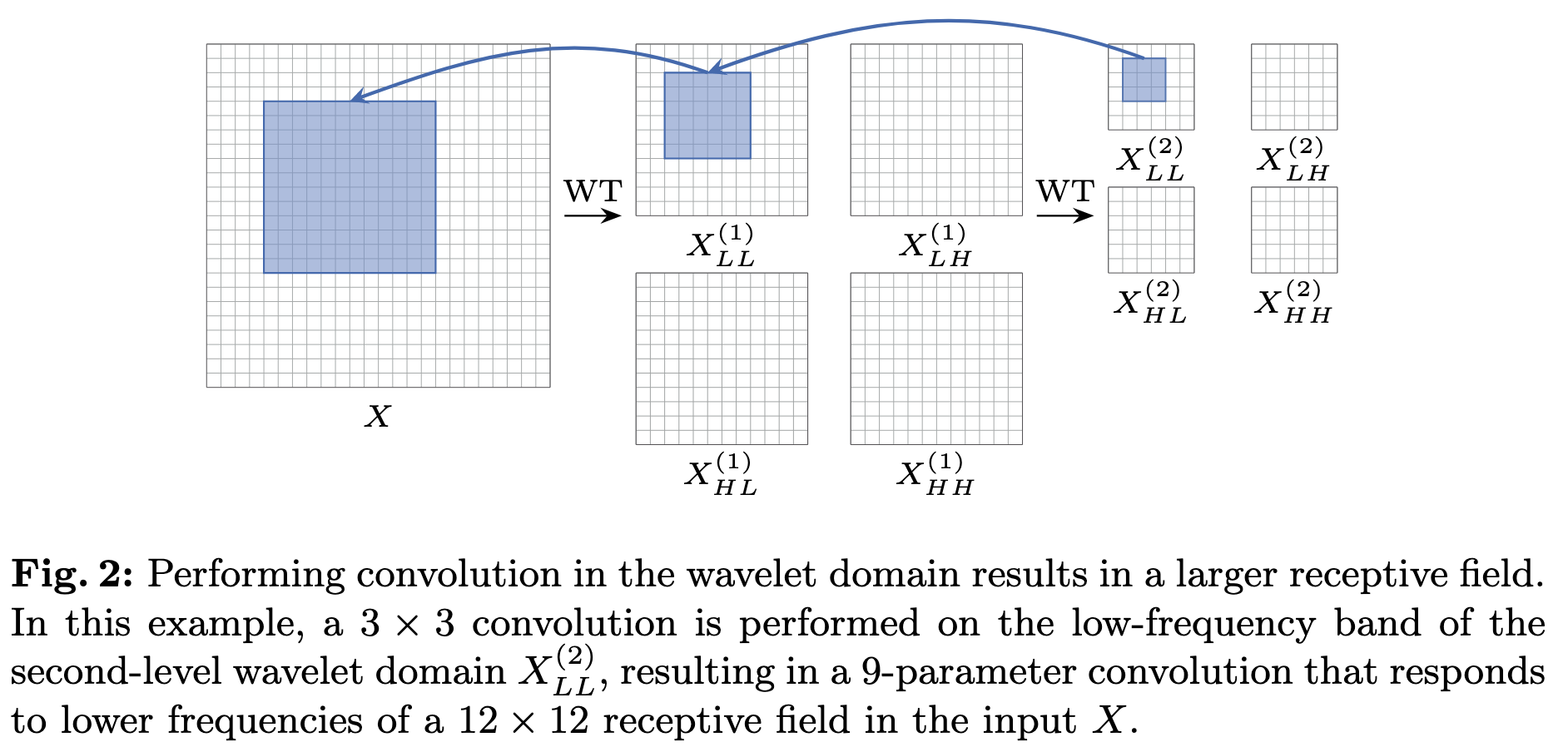
이제 cascading을 어떻게 하는지 살펴볼 차례다. $X_H$는 고주파 필터의 set일때 Eq 3.에서 살짝만 변형하여 다음과 같이 쓸 수 있다.
\[\begin{equation} X^{(i)}_{LL},\; X^{(i)}_{H} = \mathrm{WT}\!\left(X^{(i-1)}_{LL}\right) \end{equation}\] \[\begin{equation} Y^{(i)}_{LL},\; Y^{(i)}_{H} = \mathrm{Conv}\!\left( W^{(i)},\; \left(X^{(i)}_{LL},\, X^{(i)}_{H}\right) \right) \end{equation}\]convolution을 한 뒤에 결과를 합칠때는 WT와 IWT는 선형 연산이기 때문에 $IWT(X + Y) = IWT(X) + IWT(Y)$인 성질을 이용할 수 있다. 따라서 다음 수식으로 표현 할 수 있고 이를 fig 3.처럼 시각화할 수 있다.
\[\begin{equation} Z^{(i)} = \mathrm{IWT}\!\left( Y^{(i)}_{LL} + Z^{(i+1)},\; Y^{(i)}_{H} \right) \end{equation}\]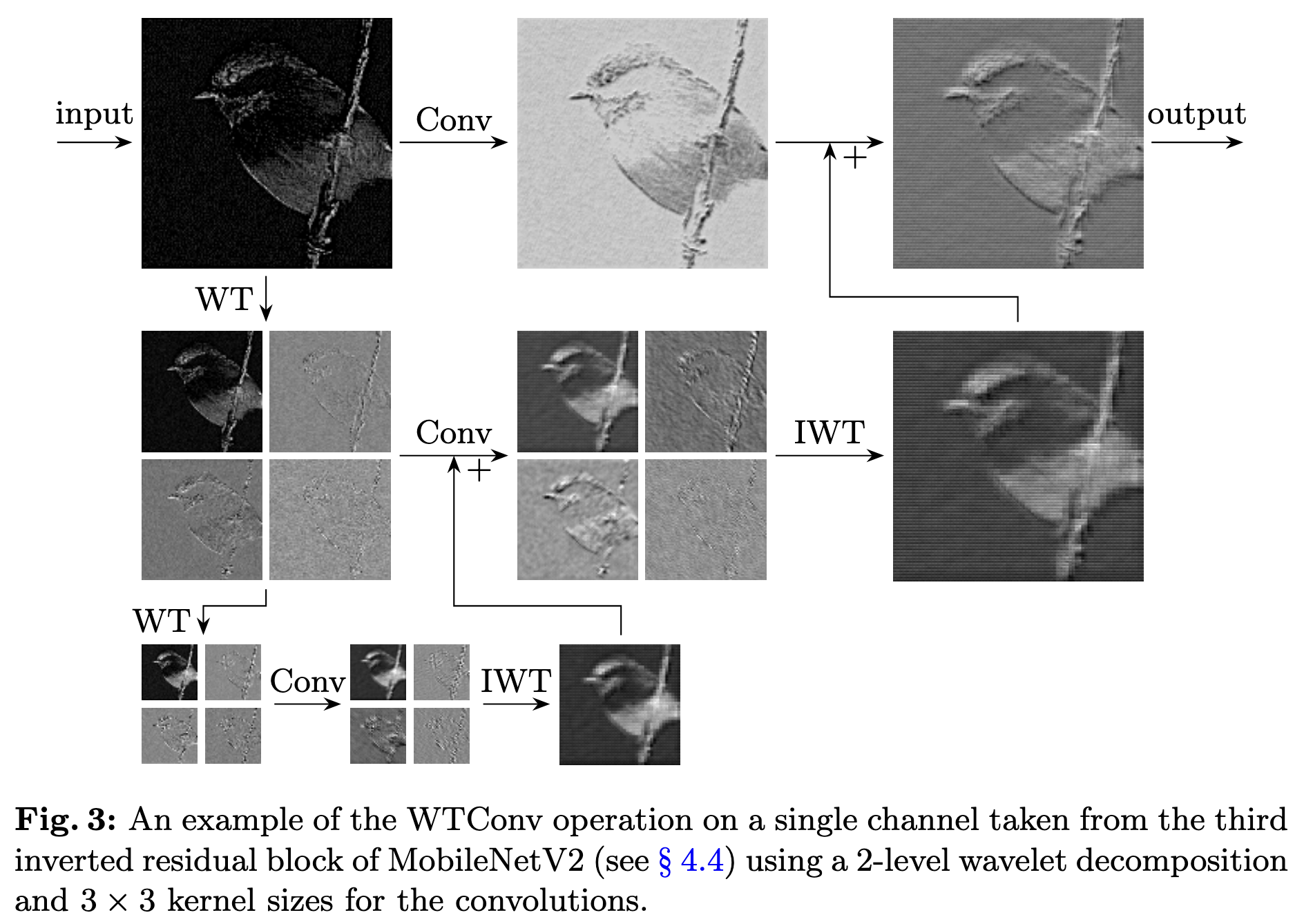
참고로 저자는 Wavelet domain의 특수성 때문에 일반적인 normalization 대신 간단한 scaling을 사용하며, 이것으로 충분하다고 언급한다(아마 선형성이 깨져서 복원이 안되기 때문에 그런 것 같은데 자세히 공부하지는 않았다.).
WTConv의 이점은 뭐가 있을까? 첫번째로 receptive field의 증가하나 학습 가능한 파라미터의 수는 줄어든다는 것이 있다. l level에서 k size의 커널을 이용하면 receptive field는 $(2^l · k)$ 만큼 증가하는 반면, 파라미터는 $(l · 4 · c · k^2)$만큼만 선형적으로 증가한다. 두번째로 WT를 반복적으로 하기 때문에 저주파가 자연스레 강조되어 standard convolution보다 저주파를 잘 잡는다. 즉 모양을 잘 잡는다.
Results
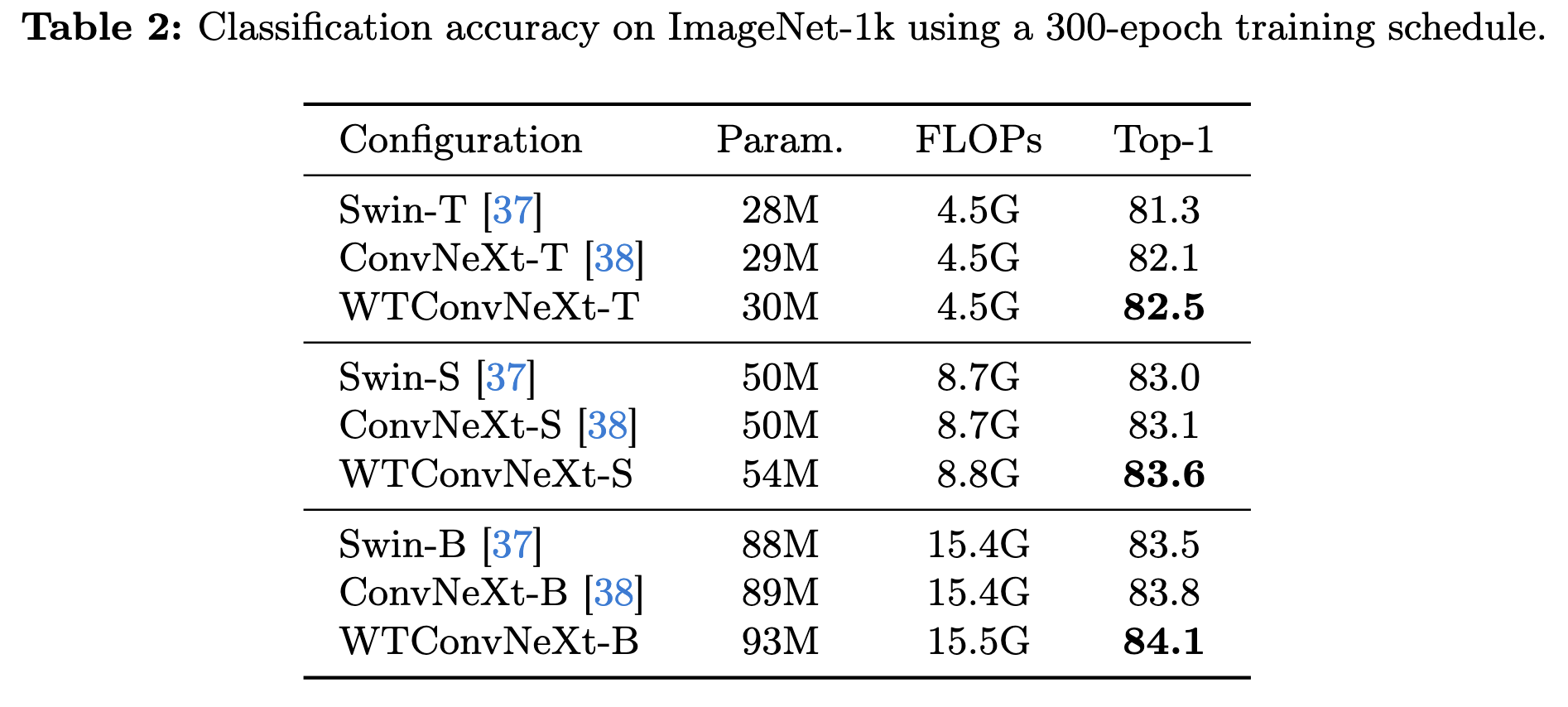
저자는 classification, semantic segmentation, object detection에 있어 ConvNeXt에 WTConv를 적용하여 학습했다. 본 post에서는 imageNet 1k에 대한 부분만 다룬다.
ImageNet-1K Classification을 위해 7×7 depth-wise convolution를 5×5 WTConv로 대체하고 level을 [5, 4, 3, 2]에 대하여 실험했다. 300epochs에 대한 결과는 다음과 같다.
WTConv Analysis
확장성:
데이터가 적을 때 WTConv가 얼마나 효율적으로 확장되는지 검증하기 위해 ImageNet-50/100/200을 사용하여 학습한다. MobileNetV2의 모든 depth-wise convolution을 WTConv 3×3 kernel로 교체하고 RepLK, GFNet, FFC와 비교를 했고 결과는 다음과 같다.
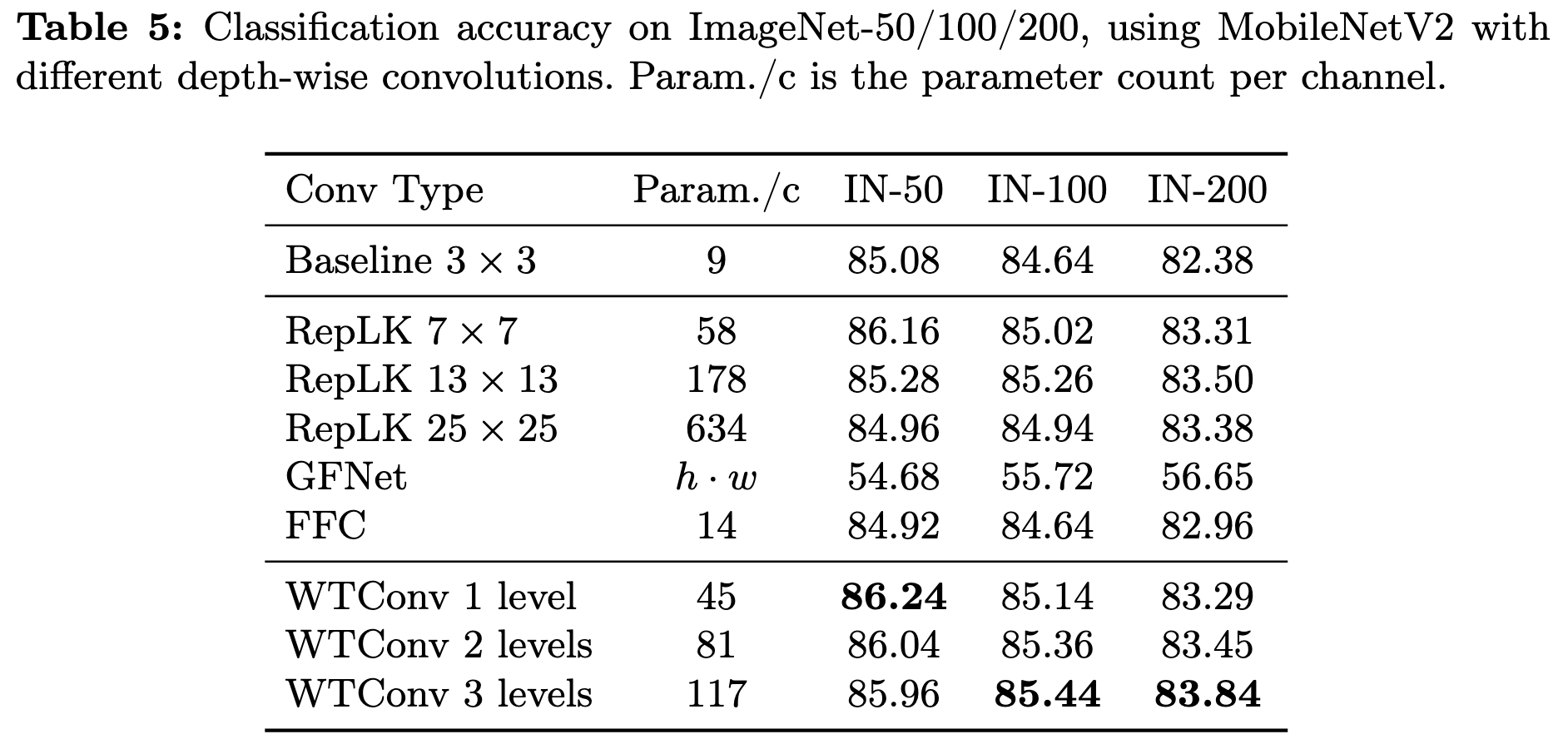
다른 방법들은 over-parameterization이 발생하지만 WTConv는 효율적이기 때문에 적은 데이터에서도 성능이 유지 된다.
강건성:
ImageNet-C/ $\bar{\text{C}}$, ImageNet-R, ImageNet-A, and ImageNet-Sketch에 대하여 classification 강건성을 검증했고, COCO 데이터셋에 corruption을 추가하여 object detection에 대한 강건성을 추가 검증했다.
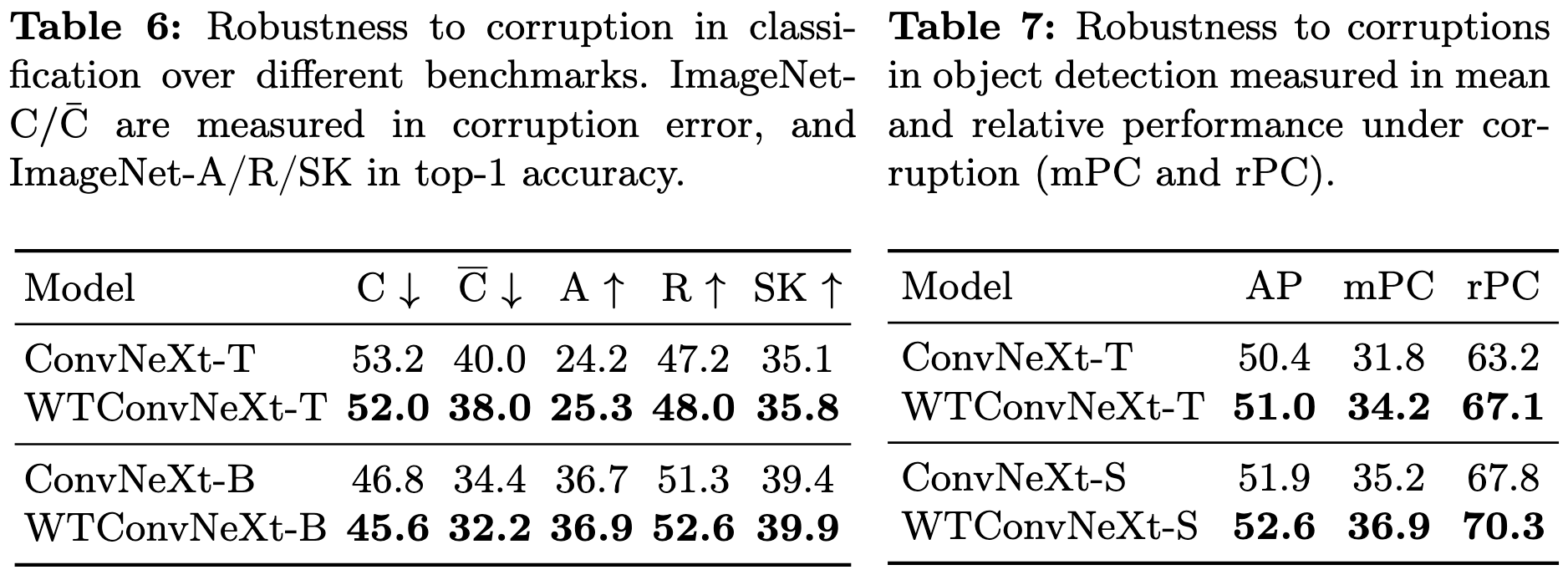
원래 데이터셋은 베이스라인에 비해 0.3~0.4 정도 차이가 난 반면 corrupted 데이터셋에 대해서는 1~2.2% 향상이 있었다. 이는 Corruption (blur, noise 등)은 주로 고주파 정보를 손상시키는데 저주파를 강조하는 WTConv 특성 때문에 핵심 정보를 잘 유지하는 것으로 보인다.
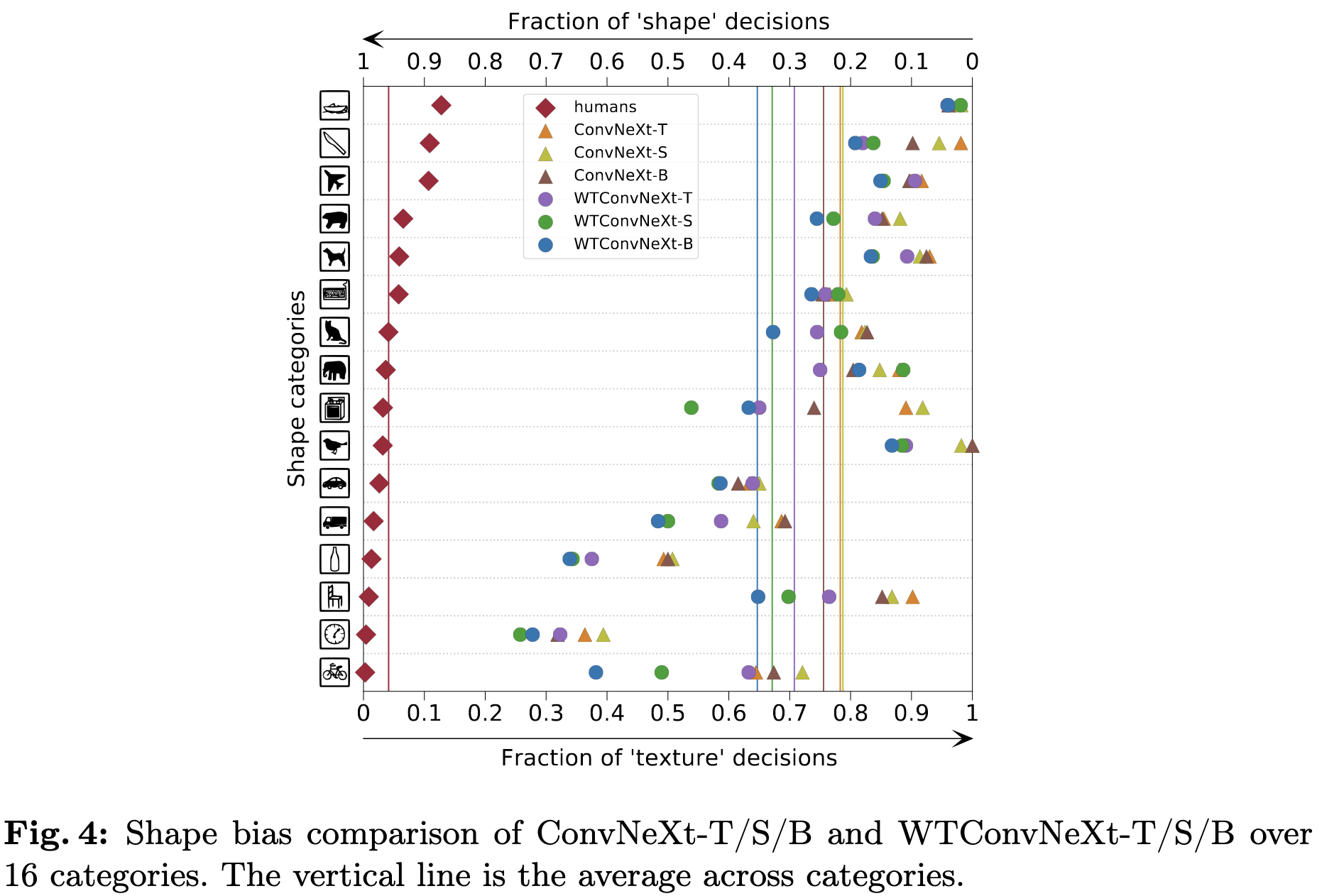
Shape-bias:
modelvshuman는 사람은 주로 shape을 보고 판단하며 CNN은 주로 texture를 보고 판단하는 것을 토대로 얼마나 사람이랑 유사하게 인지하는지 판단하게 만들어진 데이터셋이다. WTConv-T는 더 큰 ConvNeXt 네트워크보다 더 사람과 유사하게 판단했으며 이 역시 저주파를 강조하는 WTConv 특성상 나타나는 현상이라고 저자는 주장한다.
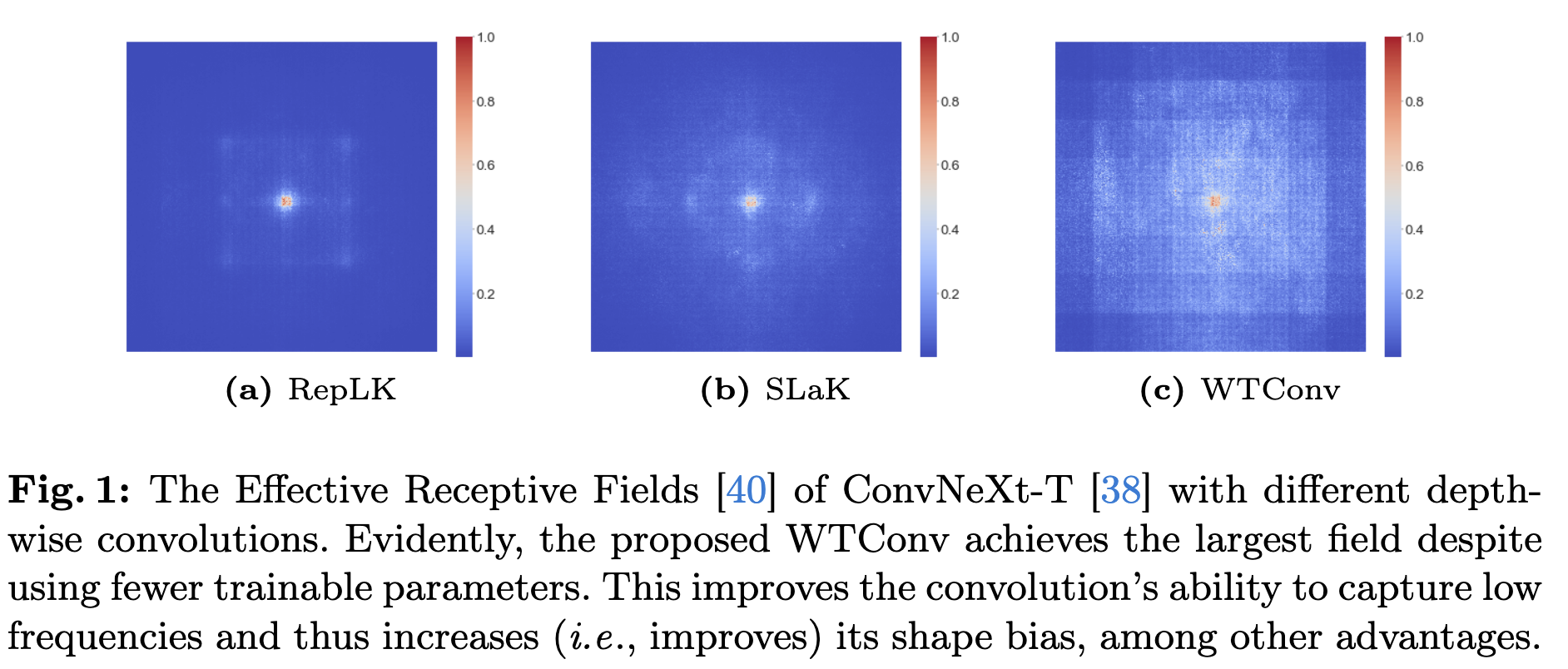
Effective Receptive Field:
이론적인 RF는 수학적으로 계산된 receptive field이며 ERF 실제로 gradient가 전달되는 영역을 의미한다. 선행연구의 방법을 그대로 사용하여 ERF를 시각화했다. ImageNet에서 50장을 랜덤 샘플링해서 $1024^2$으로 resize하여 각 픽셀의 contribution을 시각화했다.
Limitations and Conclusion
WT가 많은 FLOPS를 요구하지 않지만 WT-conv-IWT를 거쳐야 하기 때문에 실행시간이 오래 걸리는 단점이 있다. 이 부분은 병렬 처리를 하여 해결할 수 있다.
이 논문에서는 CNN이 Local 정보와 고주파만을 처리 하는 것을 해결하기 위해 WTConv를 도입한다. 이를 통해 CNN의 shape-bias를 향상시키고, noise에 강건한 네트워크를 구성하여 여러 vision tasks에서 baseline보다 좋은 성능을 보임을 확인할 수 있었다.
개인적인 생각
고전 신호 처리 기법을 이용하여 CNN의 한계를 돌파한 논문이다. 의료 분야는 데이터가 적고 취득 과정에서 많은 noise에 노출된다. 따라서 트렌드인 ViT를 사용하기가 개인적으로 꺼려졌는데 해당 layer를 도입하여 CNN을 쓰는 것이 좀 더 합리적인 방안이 될 수 있다는 생각이 든다. 참고로 2025 MICCAI에서 WTConv를 이용한 논문이 있다. WT-conv-IWT를 순차적으로 진행해야 하는 오버헤드가 있는 것은 다소 아쉽다.